Caffe | Caffe Tutorial
- Philosophy
@ In one sip, Caffe is brewed for
- Expression: models and optimizations are defined as plaintext schemas instead of code.
- Speed: for research and industry alike speed is crucial for state-of-the-art models and massive data.
- Modularity: new tasks and settings require flexibility and extension.
- Openness: scientific and applied progress call for common code, reference models, and reproducibility.
- Community: academic research, startup prototypes, and industrial applications all share strength by joint discussion and development in a BSD-2 project.
- Philosophy
- Tour
@ - Nets, Layers, and Blobs: the anatomy of a Caffe model.
@ 在 caffe 的模型里,layer 是一层层定义,从下往上是 data 层到 loss 层的过程。数据和其衍生物(derivatives)在网络层中前后传播,通过的就是 blob,它既是 array,又是 unified memory interface for the network(就像 struct)。
- 层(layer)是来自“模型”和“计算”。
- 网(net)来自 layer 和 layer 的连接。
blob 主要的任务是协助 layer 和 net 里进行存储和沟通(communicate)。
blob 首先是数据存储的 wrapper,屏蔽了 CPU 和 GPU 之间的 gap,可以定义为: “blob is an N-dimensional array stored in a C-contiguous fashion.”。
可以存储图片,模型参数(model parameters),已经 derivatives for optimization(优化过程中的产生的数据?)。
既然是 N-dim array,其计算方式为:For example, in a 4D blob, the value at index (n, k, h, w) is physically located at index
((n * K + k) * H + h) * W + w。并没有什么独特的。最前的一个维度是最大的尺度。上面的 K,H,W 是 k,h,w 的个数。看成 RGB 图片的话,就是 w,h 是宽和高, k 是 channel 数目也就是 3,n 是批处理的个数,也就是一次处理多少张图片。如果从右向左看,w,h 正好对饮 OpenCV 坐标里的 x 和 y。不同的是 OpenCV 里,图片的 rgb(顺序是 b,g,r)通常都放在一起,而不是一个 channel 一个 channel 分开。
- Number / N is the batch size of the data. Batch processing achieves better throughput for communication and device processing. For an ImageNet training batch of 256 images N = 256.
- Channel / K is the feature dimension e.g. for RGB images K = 3.
上面是说 Number(N)是数据批处理的尺寸。Channel(K)是 feature 的维度。
caffe 原来就是做图像的,所以一般都是 4D,但也可以是其他维度比如 2D。
Parameter blob dimensions vary according to the type and configuration of the layer. For a convolution layer with 96 filters of 11 x 11 spatial dimension and 3 inputs the blob is 96 x 3 x 11 x 11.
如上面,filter 的 96 x 3 x 11 x 11 一定要理解。
另外需要注意的是 matlab 里的维度不是
[n,k,h,w]而是[w,h,k,n]。For an inner product / fully-connected layer with 1000 output channels and 1024 input channels the parameter blob is 1000 x 1024.
不太理解为什么要这么定义……blob 里有两大部分,一个是 data,一个是 diff,前者是我们传进去的数据,后者是网络自己训练出来的 gradient。这些数据可以在 CPU 中,也可以在 GPU 中,数据访问可以是 const 方式,也可以是 mutable。
const Dtype* cpu_data() const; Dtype* mutable_cpu_data();再复杂一点,If you want to check out when a Blob will copy data, here is an illustrative example:
// Assuming that data are on the CPU initially, and we have a blob. // const Dtype* foo; // Dtype* bar; // foo = blob.gpu_data(); // data copied cpu->gpu. // foo = blob.cpu_data(); // no data copied since both have up-to-date contents. // bar = blob.mutable_gpu_data(); // no data copied. // // ... some operations ... // bar = blob.mutable_gpu_data(); // no data copied when we are still on GPU. // foo = blob.cpu_data(); // data copied gpu->cpu, since the gpu side has modified the data // foo = blob.gpu_data(); // no data copied since both have up-to-date contents // bar = blob.mutable_cpu_data(); // still no data copied. // bar = blob.mutable_gpu_data(); // data copied cpu->gpu. // bar = blob.mutable_cpu_data(); // data copied gpu->cpu.The layer is the essence of a model and the fundamental unit of computation. Layers convolve filters, pool, take inner products, apply nonlinearities like rectified-linear and sigmoid and other elementwise transformations, normalize, load data, and compute losses like softmax and hinge. See the layer catalogue for all operations. Most of the types needed for state-of-the-art deep learning tasks are there.
每个 layer 有三种重要的计算:setup,forward 和 backward。
- setup 是初始化时候用的,初始化 layer 以及 layer 的连接。只会调用一次。
- forward,从下往上;
- backward,从上往下;
其中 forward/backward 都有 cpu 和 gpu 的各自实现。(YangQing Jia 的 caffe2 里准备把 forward/backward 整合成为一个 run。)
Layers have two key responsibilities for the operation of the network as a whole: a forward pass that takes the inputs and produces the outputs, and a backward pass that takes the gradient with respect to the output, and computes the gradients with respect to the parameters and to the inputs, which are in turn back-propagated to earlier layers. These passes are simply the composition of each layer’s forward and backward.
- 网就是一个 DAG(有向无环图)
@ name: "LogReg" layer { name: "mnist" type: "Data" top: "data" top: "label" data_param { source: "input_leveldb" batch_size: 64 } } layer { name: "ip" type: "InnerProduct" bottom: "data" top: "ip" inner_product_param { num_output: 2 } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip" bottom: "label" top: "loss" }
首先调用
Net::Init()来初始化,立面会分别调用 layer 的layer.SetUp()来初始化 layer。整个网络的构造(construction)是 device agnostic(屏蔽了 CPU/GPU 的区别)。可以用Caffe::mode()来查询模式,用Caffe::set_mode()来设置。模型用我纯文本定义在
.prototxt文件(plaintext protocol buffer schema)里,训练后存成二进制文件.caffemodel(binaryproto)。The model format is defined by the protobuf schema in caffe.proto. The source file is mostly self-explanatory so one is encouraged to check it out.
Caffe 用了 google 的 google protocal buffer,因为它的 txt 和 binary 等价,便于阅读,而且有 C++ 和 python 的接口。
blob = {data, diff}params = [weights, biases]
- Nets, Layers, and Blobs: the anatomy of a Caffe model.
- Forward / Backward: the essential computations of layered compositional models.
@ 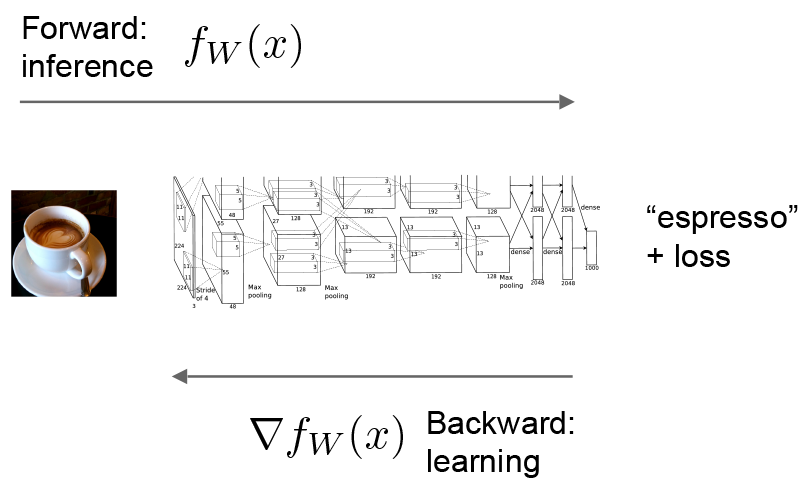
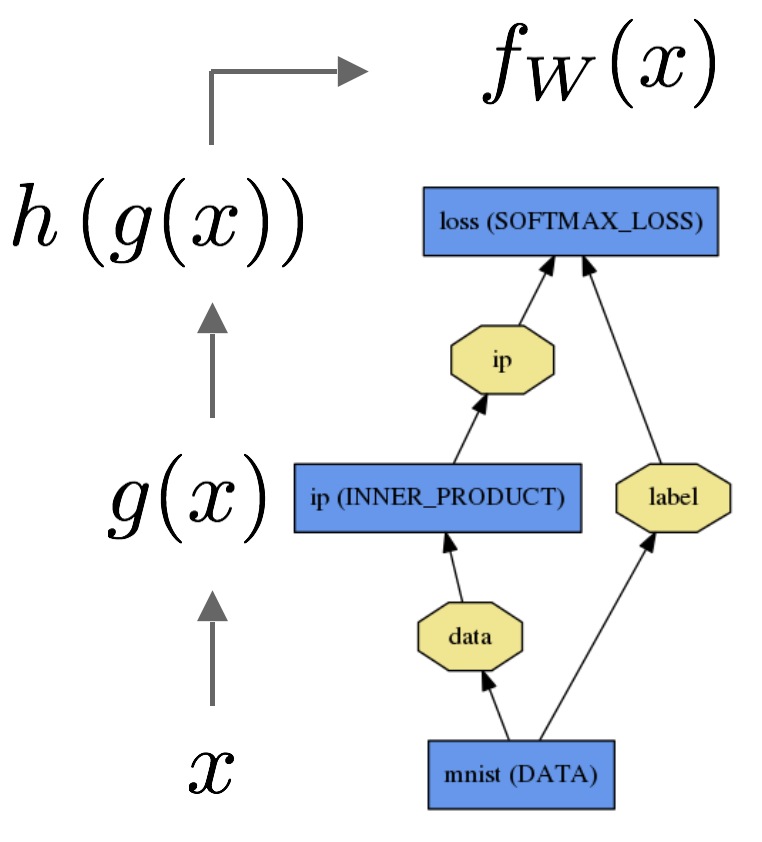
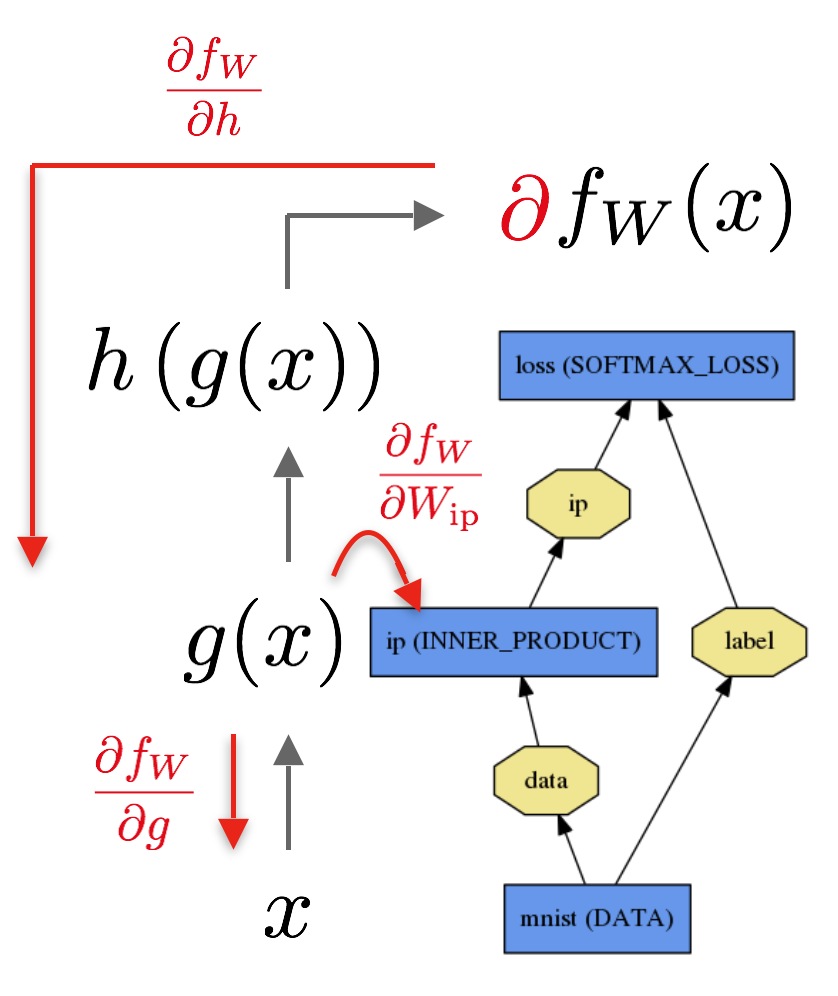
espresso,
[eˈspresəʊ], n.浓咖啡;一杯浓咖啡关于反向传播,强烈推荐这篇文章: Principles of training multi-layer neural network using backpropagation
These computations follow immediately from defining the model: Caffe plans and carries out the forward and backward passes for you.
- The
Net::Forward()andNet::Backward()methods carry out the respective passes whileLayer::Forward()andLayer::Backward()compute each step. - Every layer type has
forward_{cpu,gpu}()andbackward_{cpu,gpu}()methods to compute its steps according to the mode of computation. A layer may only implement CPU or GPU mode due to constraints or convenience.
solver 可以优化模型,听过 forward 产生 output 和 loss,通过 backward 生成模型的 gradient,然后把 gradient 考虑进模型通过试图修改 weights 来降低 loss。
Division of labor between the Solver, Net, and Layer keep Caffe modular and open to development.
上面这句话是说 solver 和 net 和 layer 各司其职,保证了 caffe 的模块化,使得它便于在原有基础上修改和再开发。
更多参见:Caffe | Layer Catalogue。这里介绍了各层的参数配置。
- The
- Forward / Backward: the essential computations of layered compositional models.
- Loss: the task to be learned is defined by the loss.
@ 机器学习里学习就是 loss 驱动的,loss 也常被称为 error,cost 以及 objective function(这个很牵强了,这是恰好你的 objective 是降低 loss 而已。)。
A loss function specifies the goal of learning by mapping parameter settings (i.e., the current network weights) to a scalar value specifying the “badness” of these parameter settings. Hence, the goal of learning is to find a setting of the weights that minimizes the loss function.
loss 函数对当前网络的参数的好坏评价(用 badness 来衡量)是优化网络的基本出发。
一个常用的 loss 函数就是 SoftmaxWithLoss,是“一个对其他”(one-versus-all),这样的一层可以用如下定义:
layer { name: "loss" type: "SoftmaxWithLoss" bottom: "pred" bottom: "label" top: "loss" }这个 top 是一个标量(scalar),也就是没有 shape 的(是不是可以把 shape 看成
[])。这里有点凌乱。说是带有
Loss后缀的 layer type 的层其实都可以算 loss(不只是最上面一层),而且默认的时候 layer 的第一个 top,的 loss weight 是 1,其他为 0。The final loss in Caffe, then, is computed by summing the total weighted loss over the network, as in the following pseudo-code:
loss := 0 for layer in layers: for top, loss_weight in layer.tops, layer.loss_weights: loss += loss_weight * sum(top)这部分一定要好好理解清楚。
- Loss: the task to be learned is defined by the loss.
- Solver: the solver coordinates model optimization.
@ 一个例子:
net: "train_val.prototxt" # 指定网络结构,这个文件有各种 layer 的设定, # 以及 `name: "net name"` test_iter: 0 test_interval: 1000000 # lr for fine-tuning should be lower than when starting from scratch #debug_info: true base_lr: 0.000001 lr_policy: "step" gamma: 0.1 iter_size: 10 # stepsize should also be lower, as we're closer to being done stepsize: 10000 display: 20 max_iter: 30001 momentum: 0.9 weight_decay: 0.0002 snapshot: 1000 snapshot_prefix: "hed" # uncomment the following to default to CPU mode solving # solver_mode: CPU- Stochastic Gradient Descent (type:
SGD), - AdaDelta (type:
AdaDelta), - Adaptive Gradient (type:
AdaGrad), - Adam (type:
Adam), - Nesterov’s Accelerated Gradient (type:
Nesterov) and - RMSprop (type:
RMSProp)
The solver
- scaffolds the optimization bookkeeping and creates the training network for learning and test network(s) for evaluation.
- iteratively optimizes by calling forward / backward and updating parameters
- (periodically) evaluates the test networks
- snapshots the model and solver state throughout the optimization
solver 通过不断调用 forward/backward,调整 parameters 来降低 loss。还可以周期性 test networks,还可以不断生成 model 和 solver state。比如 HUD 来进行边缘提取的时候,就生成了很多
hud_iter_1000.caffemodel和hud_iter_1000.solverstate文件。- calls network forward to compute the output and loss
- calls network backward to compute the gradients
- incorporates the gradients into parameter updates according to the solver method
- updates the solver state according to learning rate, history, and method
然后下面讲了不同 solver 使用的方法(一堆数学公式),以后再细看。@The solver methods address the general optimization problem of loss minimization. For dataset \(D\), the optimization objective is the average loss over all \(|D|\) data instances throughout the dataset
\[ L(W) = \frac{1}{|D|} \sum_i^{|D|} f_W\left(X^{(i)}\right) + \lambda r(W) \]
where \(f_W\left(X^{(i)}\right)\) is the loss on data instance \(X^{(i)}\) and \(r(W)\) is a regularization term with weight \(\lambda\). \(|D|\) can be very large, so in practice, in each solver iteration we use a stochastic approximation of this objective, drawing a mini-batch of \(N << |D|\) instances:
\[ L(W) \approx \frac{1}{N} \sum_i^N f_W\left(X^{(i)}\right) + \lambda r(W) \]
The model computes \(f_W\) in the forward pass and the gradient \(\nabla f_W\) in the backward pass.
The parameter update \(\Delta W\) is formed by the solver from the error gradient \(\nabla f_W\), the regularization gradient \(\nabla r(W)\), and other particulars to each method.
- Methods:
- SGD
@ Stochastic gradient descent (
type: "SGD") updates the weights \(W\) by a linear combination of the negative gradient \(\nabla L(W)\) and the previous weight update \(V_t\). The learning rate \(\alpha\) is the weight of the negative gradient. The momentum \(\mu\) is the weight of the previous update.Formally, we have the following formulas to compute the update value $ V_{t+1} $ and the updated weights $ W_{t+1} $ at iteration $ t+1 $, given the previous weight update $ V_t $ and current weights $ W_t $:
\[ V_{t+1} = \mu V_t - \alpha \nabla L(W_t) \]
\[ W_{t+1} = W_t + V_{t+1} \]
The learning “hyperparameters” (\(\alpha\) and \(\mu\)) might require a bit of tuning for best results. If you’re not sure where to start, take a look at the “Rules of thumb” below, and for further information you might refer to Leon Bottou’s Stochastic Gradient Descent Tricks.
学习率可以先设置为 α ≈ 0.01,然后慢慢降低。\(\mu\) 可以设置为 0.9。
By smoothing the weight updates across iterations, momentum tends to make deep learning with SGD both stabler and faster.
base_lr: 0.01 # 初始 lr lr_policy: "step" # 阶段下降。drop the learning rate in "steps" # by a factor of gamma every stepsize iterations gamma: 0.1 # 每个 step 降低到原来的 0.1 stepsize: 100000 # 每 100, 000 阶梯下降一次 max_iter: 350000 # train for 350K iterations total momentum: 0.9Note that the momentum setting \(\mu\) effectively multiplies the size of your updates by a factor of \(\frac{1}{1 - \mu}\) after many iterations of training, so if you increase \(\mu\), it may be a good idea to decrease \(\alpha\) accordingly (and vice versa).
For example, with \(\mu = 0.9\), we have an effective update size multiplier of \(\frac{1}{1 - 0.9} = 10\). If we increased the momentum to \(\mu = 0.99\), we’ve increased our update size multiplier to 100, so we should drop \(\alpha\) (
base_lr) by a factor of 10.
- SGD
- AdaDelta
@ The AdaDelta (
type: "AdaDelta") method (M. Zeiler) is a “robust learning rate method”. It is a gradient-based optimization method (like SGD). The update formulas are\[ \begin{align} (v_t)_i &= \frac{\operatorname{RMS}((v_{t-1})_i)}{\operatorname{RMS}\left( \nabla L(W_t) \right)_{i}} \left( \nabla L(W_{t'}) \right)_i \\ \operatorname{RMS}\left( \nabla L(W_t) \right)_{i} &= \sqrt{E[g^2] + \varepsilon} \\ E[g^2]_t &= \delta{E[g^2]_{t-1} } + (1-\delta)g_{t}^2 \end{align} \]
and
\[ (W_{t+1})_i = (W_t)_i - \alpha (v_t)_i. \]
- AdaDelta
- AdaGrad
@ The adaptive gradient (
type: "AdaGrad") method (Duchi et al.) is a gradient-based optimization method (like SGD) that attempts to “find needles in haystacks in the form of very predictive but rarely seen features,” in Duchi et al.’s words.Given the update information from all previous iterations \[ \left( \nabla L(W) \right)_{t'} \] for \[ t' \in \{1, 2, ..., t\} \], the update formulas proposed by are as follows, specified for each component \[i\] of the weights \[W\]:
\[ (W_{t+1})_i = (W_t)_i - \alpha \frac{\left( \nabla L(W_t) \right)_{i}}{ \sqrt{\sum_{t'=1}^{t} \left( \nabla L(W_{t'}) \right)_i^2} } \]
- AdaGrad
- Adam
@ like SGD.
- Adam
- NAG
@ Nesterov’s accelerated gradient
- NAG
- RMSprop
like SGD.
Scaffolding@- The solver scaffolding prepares the optimization method and initializes the model to be learned in
Solver::Presolve().@ >>> caffe train -solver examples/mnist/lenet_solver.prototxt I0902 13:35:56.474978 16020 caffe.cpp:90] Starting Optimization I0902 13:35:56.475190 16020 solver.cpp:32] Initializing solver from parameters: test_iter: 100 test_interval: 500 base_lr: 0.01 display: 100 max_iter: 10000 lr_policy: "inv" gamma: 0.0001 power: 0.75 momentum: 0.9 weight_decay: 0.0005 snapshot: 5000 snapshot_prefix: "examples/mnist/lenet" solver_mode: GPU net: "examples/mnist/lenet_train_test.prototxt"
- The solver scaffolding prepares the optimization method and initializes the model to be learned in
- Net initialization
@ I0902 13:35:56.655681 16020 solver.cpp:72] Creating training net from net file: examples/mnist/lenet_train_test.prototxt [...] I0902 13:35:56.656740 16020 net.cpp:56] Memory required for data: 0 I0902 13:35:56.656791 16020 net.cpp:67] Creating Layer mnist I0902 13:35:56.656811 16020 net.cpp:356] mnist -> data I0902 13:35:56.656846 16020 net.cpp:356] mnist -> label I0902 13:35:56.656874 16020 net.cpp:96] Setting up mnist I0902 13:35:56.694052 16020 data_layer.cpp:135] Opening lmdb examples/mnist/mnist_train_lmdb I0902 13:35:56.701062 16020 data_layer.cpp:195] output data size: 64,1,28,28 I0902 13:35:56.701146 16020 data_layer.cpp:236] Initializing prefetch I0902 13:35:56.701196 16020 data_layer.cpp:238] Prefetch initialized. I0902 13:35:56.701212 16020 net.cpp:103] Top shape: 64 1 28 28 (50176) I0902 13:35:56.701230 16020 net.cpp:103] Top shape: 64 1 1 1 (64) [...] I0902 13:35:56.703737 16020 net.cpp:67] Creating Layer ip1 I0902 13:35:56.703753 16020 net.cpp:394] ip1 <- pool2 I0902 13:35:56.703778 16020 net.cpp:356] ip1 -> ip1 I0902 13:35:56.703797 16020 net.cpp:96] Setting up ip1 I0902 13:35:56.728127 16020 net.cpp:103] Top shape: 64 500 1 1 (32000) I0902 13:35:56.728142 16020 net.cpp:113] Memory required for data: 5039360 I0902 13:35:56.728175 16020 net.cpp:67] Creating Layer relu1 I0902 13:35:56.728194 16020 net.cpp:394] relu1 <- ip1 I0902 13:35:56.728219 16020 net.cpp:345] relu1 -> ip1 (in-place) I0902 13:35:56.728240 16020 net.cpp:96] Setting up relu1 I0902 13:35:56.728256 16020 net.cpp:103] Top shape: 64 500 1 1 (32000) I0902 13:35:56.728270 16020 net.cpp:113] Memory required for data: 5167360 I0902 13:35:56.728287 16020 net.cpp:67] Creating Layer ip2 I0902 13:35:56.728304 16020 net.cpp:394] ip2 <- ip1 I0902 13:35:56.728333 16020 net.cpp:356] ip2 -> ip2 I0902 13:35:56.728356 16020 net.cpp:96] Setting up ip2 I0902 13:35:56.728690 16020 net.cpp:103] Top shape: 64 10 1 1 (640) I0902 13:35:56.728705 16020 net.cpp:113] Memory required for data: 5169920 I0902 13:35:56.728734 16020 net.cpp:67] Creating Layer loss I0902 13:35:56.728747 16020 net.cpp:394] loss <- ip2 I0902 13:35:56.728767 16020 net.cpp:394] loss <- label I0902 13:35:56.728786 16020 net.cpp:356] loss -> loss I0902 13:35:56.728811 16020 net.cpp:96] Setting up loss I0902 13:35:56.728837 16020 net.cpp:103] Top shape: 1 1 1 1 (1) I0902 13:35:56.728849 16020 net.cpp:109] with loss weight 1 I0902 13:35:56.728878 16020 net.cpp:113] Memory required for data: 5169924
- Net initialization
- Loss
@ I0902 13:35:56.728893 16020 net.cpp:170] loss needs backward computation. I0902 13:35:56.728909 16020 net.cpp:170] ip2 needs backward computation. I0902 13:35:56.728924 16020 net.cpp:170] relu1 needs backward computation. I0902 13:35:56.728938 16020 net.cpp:170] ip1 needs backward computation. I0902 13:35:56.728953 16020 net.cpp:170] pool2 needs backward computation. I0902 13:35:56.728970 16020 net.cpp:170] conv2 needs backward computation. I0902 13:35:56.728984 16020 net.cpp:170] pool1 needs backward computation. I0902 13:35:56.728998 16020 net.cpp:170] conv1 needs backward computation. I0902 13:35:56.729014 16020 net.cpp:172] mnist does not need backward computation. I0902 13:35:56.729027 16020 net.cpp:208] This network produces output loss I0902 13:35:56.729053 16020 net.cpp:467] Collecting Learning Rate and Weight Decay. I0902 13:35:56.729071 16020 net.cpp:219] Network initialization done. I0902 13:35:56.729085 16020 net.cpp:220] Memory required for data: 5169924 I0902 13:35:56.729277 16020 solver.cpp:156] Creating test net (#0) specified by net file: examples/mnist/lenet_train_test.prototxt
- Loss
- Completion
@ I0902 13:35:56.806970 16020 solver.cpp:46] Solver scaffolding done. I0902 13:35:56.806984 16020 solver.cpp:165] Solving LeNet
- Completion
- Updating Parameters:
权重的更新(weight update)是 solver 提交给的 net,调用的函数是
Solver::ComputeUpdateValue()。The
ComputeUpdateValuemethod incorporates any weight decay \[ r(W) \] into the weight gradients (which currently just contain the error gradients) to get the final gradient with respect to each network weight. Then these gradients are scaled by the learning rate \[ \alpha \] and the update to subtract is stored in each parameter Blob’sdifffield. Finally, theBlob::Updatemethod is called on each parameter blob, which performs the final update (subtracting the Blob’sdifffrom itsdata).- Snapshotting and Resuming:
@ The solver snapshots the weights and its own state during training in
Solver::Snapshot()andSolver::SnapshotSolverState(). The weight snapshots export the learned model while the solver snapshots allow training to be resumed from a given point. Training is resumed bySolver::Restore()andSolver::RestoreSolverState().Weights are saved without extension while solver states are saved with
.solverstateextension. Both files will have an_iter_Nsuffix for the snapshot iteration number.Snapshotting is configured by:
# The snapshot interval in iterations. snapshot: 5000 # File path prefix for snapshotting model weights and solver state. # Note: this is relative to the invocation of the `caffe` utility, not the # solver definition file. snapshot_prefix: "/path/to/model" # Snapshot the diff along with the weights. This can help debugging training # but takes more storage. snapshot_diff: false # A final snapshot is saved at the end of training unless # this flag is set to false. The default is true. snapshot_after_train: truein the solver definition prototxt.
- Stochastic Gradient Descent (type:
- Solver: the solver coordinates model optimization.
- Layer Catalogue: the layer is the fundamental unit of modeling and computation – Caffe’s catalogue includes layers for state-of-the-art models.
@ 这里讲得很详细,介绍了每个层有哪些 required 参数,有哪些 optional 参数。头文件,以及 CPU/GPU 实现的文件。
- caffe.proto
@ 所有的 layers 都定义在 caffe:/src/caffe/layers。
my noteed source code: include/caffe-annotated.md
# cd $CAFFE_ROOT >>> ls src/caffe/layers/*loss*.cpp src/caffe/layers/contrastive_loss_layer.cpp src/caffe/layers/euclidean_loss_layer.cpp src/caffe/layers/hinge_loss_layer.cpp src/caffe/layers/infogain_loss_layer.cpp src/caffe/layers/loss_layer.cpp src/caffe/layers/multinomial_logistic_loss_layer.cpp src/caffe/layers/sigmoid_cross_entropy_loss_layer.cpp src/caffe/layers/softmax_loss_layer.cpp >>> ls src/caffe/layers/*loss*.cu src/caffe/layers/contrastive_loss_layer.cu src/caffe/layers/euclidean_loss_layer.cu src/caffe/layers/sigmoid_cross_entropy_loss_layer.cu src/caffe/layers/softmax_loss_layer.cu
@- 所有的 layers
@ - Vision Layers
@ 输入的是三维的
w*h*c的图片,输出一个一维的w*h*c的 big vector。ignore the spatial structure of the input
- 卷积层,
Convolution@ implemetaion
- /src/caffe/layers/convolution_layer.cpp
- /src/caffe/layers/convolution_layer.cpp
sig:
[n * c_i * h_i * w_i]->[n * c_o * h_o * w_o],where
h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1- 一个 prototxt 例子,来自 ./models/bvlc_reference_caffenet/train_val.prototxt
@ layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" # learning rate and decay multipliers for the filters param { lr_mult: 1 decay_mult: 1 } # learning rate and decay multipliers for the biases param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 96 # learn 96 filters kernel_size: 11 # each filter is 11x11 stride: 4 # step 4 pixels between each filter application weight_filler { type: "gaussian" # initialize the filters from a Gaussian std: 0.01 # distribution with stdev 0.01 (default mean: 0) } bias_filler { type: "constant" # initialize the biases to zero (0) value: 0 } } }
weight_fillerbias_termstridegroup
- 卷积层,
- 池化层,
Pooling@ sig:
[n * c * h_i * w_i]->[n * c * h_o * w_o]layer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 # pool over a 3x3 region stride: 2 # step two pixels (in the bottom blob) between pooling regions } }池化方法有 MAX, AVE, or STOCHASTIC
- 池化层,
- Local Response Normalization,
LRN@ The local response normalization layer performs a kind of “lateral inhibition”
[.ɪnhɪ'bɪʃ(ə)n]n.抑制;禁止;拘谨;拘束感 by normalizing over local input regions. InACROSS_CHANNELSmode, the local regions extend across nearby channels, but have no spatial extent (i.e., they have shapelocal_size x 1 x 1). InWITHIN_CHANNELmode, the local regions extend spatially, but are in separate channels (i.e., they have shape1 x local_size x local_size). Each input value is divided by \((1+(α/n)∑_ix^2_i)^β\), where n is the size of each local region, and the sum is taken over the region centered at that value (zero padding is added where necessary).
- Local Response Normalization,
- im2col
@ Im2col is a helper for doing the image-to-column transformation that you most likely do not need to know about. This is used in Caffe’s original convolution to do matrix multiplication by laying out all patches into a matrix.
- im2col
- Vision Layers
- Loss Layers
@ Softmax,
SoftmaxWithLossSum-of-Squares / Euclidean,
EuclideanLossHinge / Margin,
HingeLoss
- Loss Layers
- Activation / Neuron Layers
@ In general, activation / Neuron layers are element-wise operators, taking one bottom blob and producing one top blob of the same size. In the layers below, we will ignore the input and out sizes as they are identical: { input, output: n * c * h * w }.
ReLU / Rectified-Linear and Leaky-ReLU,
ReLUmax(0, x)
Sigmoid,
Sigmoidsigmoid(x)
TanH / Hyperbolic Tangent,
TanHAbsolute Value,
AbsValPower,
Powerpower(x, power=1, scale=1, shift=0) = (shift+scale*x)^powerBNLL,
BNLLThe BNLL (binomial normal log likelihood) layer computes the output as
log(1 + exp(x))for each input element x.
- Activation / Neuron Layers
- Data Layers
@ Data enters Caffe through data layers: they lie at the bottom of nets. Data can come from efficient databases (LevelDB or LMDB), directly from memory, or, when efficiency is not critical, from files on disk in HDF5 or common image formats.
Database,
DataIn-Memory,
MemoryDataHDF5 Input,
HDF5DataHDF5 Output,
HDF5OutputImages,
ImageDatasource: name of a text file, with each line giving an image filename and label
Dummy,
DummyDataDummyDatais for development and debugging. SeeDummyDataParam.
- Data Layers
- Common Layers
@ - Inner Product,
InnerProduct@ The InnerProduct layer (also usually referred to as the fully connected layer) treats the input as a simple vector and produces an output in the form of a single vector (with the blob’s height and width set to 1).
sig:
[ n * c_i * h_i * w_i ]->[n * c_o * 1 * 1]layer { name: "fc8" type: "InnerProduct" # learning rate and decay multipliers for the weights param { lr_mult: 1 decay_mult: 1 } # learning rate and decay multipliers for the biases param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 1000 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } bottom: "fc7" top: "fc8" }简单的说,对 ip 层而言,所有的 feature 都看成一串数字(
c*h*w), ip 层的任务是学习c_o个同样大小(c*h*w)的权重。
- Inner Product,
- Splitting,
Split@ 就是 split 咯。
- Splitting,
- Flattening,
Flatten@ sig:
[n * c * h * w]->[n * (c*h*w)]
- Flattening,
- Reshape,
Reshape@ As another example, specifying
reshape_param { shape { dim: 0 dim: -1 } }makes the layer behave in exactly the same way as the Flatten layer.layer { name: "reshape" type: "Reshape" bottom: "input" top: "output" reshape_param { shape { dim: 0 # copy the dimension from below dim: 2 dim: 3 dim: -1 # infer it from the other dimensions } } }
- Reshape,
- Concatenation,
Concat@ 可以用来把好几个 bottom 的数据合起来。
axis, {0, 1}, 0 for n, 1 for c.[n_i * c_i * h * w]- 如果 c 都一样,而且 axis = 0: 就把所有都数据串联起来,输出为:
[(n_1 + n_2 + ... + n_K) * c_1 * h * w] - 如果 n 都一样,而且 axis = 1:就把每组数据的 c 个 feature 串联起来,输出为:
[n_1 * (c_1 + c_2 + ... + c_K) * h * w]
layer { name: "concat" bottom: "in1" bottom: "in2" top: "out" type: "Concat" concat_param { axis: 1 # 把 feature 合起来,n 不变。 } }
- Concatenation,
- Slicing
@ layer { name: "slicer_label" type: "Slice" bottom: "label" ## Example of label with a shape N x 3 x 1 x 1 top: "label1" top: "label2" top: "label3" slice_param { axis: 1 slice_point: 1 slice_point: 2 } }
- Slicing
- Elementwise Operations
- ArgMax
- SoftMax
- Mean-Variance Normalization
- Common Layers
- caffe.proto
- Layer Catalogue: the layer is the fundamental unit of modeling and computation – Caffe’s catalogue includes layers for state-of-the-art models.
- Interfaces: command line, Python, and MATLAB Caffe.
@ 命令行,在
caffe/build/tools文件夹。caffeTraining:
caffe trainlearns models from scratch, resumes learning from saved snapshots, and fine-tunes models to new data and tasks:- 设置 solver:
-solver solver.prototxt - 从 snapshot 继续训练:
-snapshot model_iter_1000.solverstate - 初始化:
-weights model.caffemodel
Testing
Benchmarking
- Diagnostics
>>> ./build/tools/caffe device_query -gpu 0 I0617 17:51:26.008927 31605 caffe.cpp:112] Querying GPUs 0 I0617 17:51:26.015770 31605 common.cpp:168] Device id: 0 I0617 17:51:26.015813 31605 common.cpp:169] Major revision number: 5 I0617 17:51:26.015820 31605 common.cpp:170] Minor revision number: 2 I0617 17:51:26.015825 31605 common.cpp:171] Name: GeForce GTX TITAN X I0617 17:51:26.015831 31605 common.cpp:172] Total global memory: 12884705280 I0617 17:51:26.015837 31605 common.cpp:173] Total shared memory per block: 49152 I0617 17:51:26.015843 31605 common.cpp:174] Total registers per block: 65536 I0617 17:51:26.015848 31605 common.cpp:175] Warp size: 32 I0617 17:51:26.015853 31605 common.cpp:176] Maximum memory pitch: 2147483647 I0617 17:51:26.015861 31605 common.cpp:177] Maximum threads per block: 1024 I0617 17:51:26.015866 31605 common.cpp:178] Maximum dimension of block: 1024, 1024, 64 I0617 17:51:26.015872 31605 common.cpp:181] Maximum dimension of grid: 2147483647, 65535, 65535 I0617 17:51:26.015877 31605 common.cpp:184] Clock rate: 1076000 I0617 17:51:26.015882 31605 common.cpp:185] Total constant memory: 65536 I0617 17:51:26.015893 31605 common.cpp:186] Texture alignment: 512 I0617 17:51:26.015899 31605 common.cpp:187] Concurrent copy and execution: Yes I0617 17:51:26.015907 31605 common.cpp:189] Number of multiprocessors: 24 I0617 17:51:26.015911 31605 common.cpp:190] Kernel execution timeout: No >>> ./build/tools/caffe device_query -gpu 1 I0617 16:58:12.442965 31520 caffe.cpp:112] Querying GPUs 1 I0617 16:58:12.713518 31520 common.cpp:168] Device id: 1 I0617 16:58:12.713558 31520 common.cpp:169] Major revision number: 5 I0617 16:58:12.713564 31520 common.cpp:170] Minor revision number: 2 I0617 16:58:12.713570 31520 common.cpp:171] Name: GeForce GTX TITAN X I0617 16:58:12.713575 31520 common.cpp:172] Total global memory: 12884180992 I0617 16:58:12.713582 31520 common.cpp:173] Total shared memory per block: 49152 I0617 16:58:12.713587 31520 common.cpp:174] Total registers per block: 65536 I0617 16:58:12.713593 31520 common.cpp:175] Warp size: 32 I0617 16:58:12.713598 31520 common.cpp:176] Maximum memory pitch: 2147483647 I0617 16:58:12.713603 31520 common.cpp:177] Maximum threads per block: 1024 I0617 16:58:12.713608 31520 common.cpp:178] Maximum dimension of block: 1024, 1024, 64 I0617 16:58:12.713613 31520 common.cpp:181] Maximum dimension of grid: 2147483647, 65535, 65535 I0617 16:58:12.713618 31520 common.cpp:184] Clock rate: 1076000 I0617 16:58:12.713623 31520 common.cpp:185] Total constant memory: 65536 I0617 16:58:12.713627 31520 common.cpp:186] Texture alignment: 512 I0617 16:58:12.713634 31520 common.cpp:187] Concurrent copy and execution: Yes I0617 16:58:12.713640 31520 common.cpp:189] Number of multiprocessors: 24 I0617 16:58:12.713646 31520 common.cpp:190] Kernel execution timeout: Yes- Parallelism
# train on GPUs 0 & 1 (doubling the batch size) caffe train -solver examples/mnist/lenet_solver.prototxt -gpu 0,1 # train on all GPUs (multiplying batch size by number of devices) caffe train -solver examples/mnist/lenet_solver.prototxt -gpu all
- 设置 solver:
Python
- caffe.Net is the central interface for loading, configuring, and running models. caffe.Classifier and caffe.Detector provide convenience interfaces for common tasks.
- caffe.SGDSolver exposes the solving interface.
- caffe.io handles input / output with preprocessing and protocol buffers.
- caffe.draw visualizes network architectures.
- Caffe blobs are exposed as numpy ndarrays for ease-of-use and efficiency.
Matlab
caffe, single precision. matlab:
[w, h, c, n]instead of[n, c, h, w]TODO
- Interfaces: command line, Python, and MATLAB Caffe.
- Data: how to caffeinate data for model input.
@ Data flows through Caffe as Blobs. Data layers load input and save output by converting to and from Blob to other formats. Common transformations like mean-subtraction and feature-scaling are done by data layer configuration. New input types are supported by developing a new data layer – the rest of the Net follows by the modularity of the Caffe layer catalogue.
- load MNIST digits
@ layer { name: "mnist" # Data layer loads leveldb or lmdb storage DBs for high-throughput. type: "Data" # the 1st top is the data itself: the name is only convention top: "data" # the 2nd top is the ground truth: the name is only convention top: "label" # the Data layer configuration data_param { # path to the DB source: "examples/mnist/mnist_train_lmdb" # type of DB: LEVELDB or LMDB (LMDB supports concurrent reads) backend: LMDB # batch processing improves efficiency. batch_size: 64 } # common data transformations transform_param { # feature scaling coefficient: this maps the [0, 255] MNIST data to [0, 1] scale: 0.00390625 } }
tops and bottoms
data and label
- Transformations
layer { name: "data" type: "Data" [...] transform_param { scale: 0.1 mean_file_size: mean.binaryproto # for images in particular horizontal mirroring and random cropping # can be done as simple data augmentations. mirror: 1 # 1 = on, 0 = off # crop a `crop_size` x `crop_size` patch: # - at random during training # - from the center during testing crop_size: 227 } }
Prefetching
pre-fetching, for throughput data layers fetch the next batch of data and prepare it in the background while the Net computes the current batch.
Multiple Inputs
- load MNIST digits
- Data: how to caffeinate data for model input.
- Tour
- Deeper Learning
@ some tutorial on deeper learning.
- Deeper Learning
refs and see also