System & Network & MISC
I have dreams, and regardless of whether or not they’re realistic, I must work toward them.
System
Network
MISC
- JiuZhang
@ - 我为什么放弃 Google Offer ? - 九章算法 - 知乎专栏
@ 刷题方面,跟着九章课程的节奏来准备算法和数据结构的复习并配合 lintcode 来刷题就好啦。
- 我为什么放弃 Google Offer ? - 九章算法 - 知乎专栏
- JiuZhang
- 有病治病,没病强身
@ 看你做什么了。花一天把
fork,exec,mknod,pipe,open,close,read,write,socket,bind,listen,accept,connect,epoll *,signal,pthread *,boost.coroutine写点样例熟悉一遍,有病治病,没病强身。- fork - create a child process
@ man fork
#include <unistd.h> pid_t fork(void);fork()creates a new process by duplicating the calling process. The new process, referred to as the child, is an exact duplicate of the calling process, referred to as the parent, except for the following points:- The child has its own unique process ID, and this PID does not match the ID of any existing process group.
- The child’s parent process ID is the same as the parent’s process ID.
- The child does not inherit its parent’s memory locks.
- Process resource utilizations and CPU time counters are reset to zero in the child.
- The child’s set of pending signals is initially empty.
- The child does not inherit semaphore adjustments from its parent.
- The child does not inherit record locks from its parent.
- The child does not inherit timers from its parent.
- The child does not inherit outstanding asynchronous I/O operations from its parent, nor does it inherit any asynchronous I/O contexts from its parent
- execl, execlp, execle, execv, execvp, execvpe - execute a file
@ man exec
#include <unistd.h> extern char **environ; int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg, ..., char * const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execvpe(const char *file, char *const argv[], char *const envp[]);The exec() family of functions replaces the current process image with a new process image. The functions described in this manual page are front-ends for execve(2). (See the manual page for execve(2) for further details about the replacement of the current process image.)
The initial argument for these functions is the name of a file that is to be executed.
The const char arg and subsequent ellipses in the execl(), execlp(), and execle() functions can be thought of as arg0, arg1, …, argn. Together they describe a list of one or more pointers to null-terminated strings that represent the argument list available to the executed program. The first argument, by convention, should point to the filename associated with the file being executed. The list of arguments must be terminated by a NULL pointer, and, since these are variadic functions, this pointer must be cast (char ) NULL.
The execv(), execvp(), and execvpe() functions provide an array of pointers to null-terminated strings that represent the argument list available to the new program. The first argument, by convention, should point to the filename associated with the file being executed. The array of pointers must be terminated by a NULL pointer.
- mknod - create a special or ordinary file
@ man 2 mknod
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> int mknod(const char *pathname, mode_t mode, dev_t dev);The system call mknod() creates a filesystem node (file, device special file or named pipe) named pathname, with attributes specified by mode and dev.
The mode argument specifies both the permissions to use and the type of node to be created. It should be a combination (using bitwise OR) of one of the file types listed below and the permissions for the new node.
The permissions are modified by the process’s umask in the usual way: the permissions of the created node are (mode & ~umask).
The file type must be one of S_IFREG, S_IFCHR, S_IFBLK, S_IFIFO or S_IFSOCK to specify a regular file (which will be created empty), character special file, block special file, FIFO (named pipe), or UNIX domain socket, respectively. (Zero file type is equivalent to type S_IFREG.)
If the file type is S_IFCHR or S_IFBLK then dev specifies the major and minor numbers of the newly created device special file (makedev(3) may be useful to build the value for dev); otherwise it is ignored.
If pathname already exists, or is a symbolic link, this call fails with an EEXIST error.
The newly created node will be owned by the effective user ID of the process. If the directory containing the node has the set-group-ID bit set, or if the filesystem is mounted with BSD group semantics, the new node will inherit the group ownership from its parent directory; otherwise it will be owned by the effective group ID of the process.
- pipe, pipe2 - create pipe
@ man pipe
#include <unistd.h> int pipe(int pipefd); #define _GNU_SOURCE /* See feature_test_macros(7) */ #include <fcntl.h> /* Obtain O_* constant definitions */ #include <unistd.h> int pipe2(int pipefd, int flags);pipe() creates a pipe, a unidirectional data channel that can be used for interprocess communication. The array pipefd is used to return two file descrip‐tors referring to the ends of the pipe. pipefd refers to the read end of the pipe. pipefd refers to the write end of the pipe. Data written to the write end of the pipe is buffered by the kernel until it is read from the read end of the pipe. For further details, see pipe(7).
If flags is 0, then pipe2() is the same as pipe(). The following values can be bitwise ORed in flags to obtain different behavior:
O_NONBLOCK Set the O_NONBLOCK file status flag on the two new open file descriptions. Using this flag saves extra calls to fcntl(2) to achieve the same result.
O_CLOEXEC Set the close-on-exec (FD_CLOEXEC) flag on the two new file descriptors. See the description of the same flag in open(2) for reasons why this may be useful.
The following program creates a pipe, and then fork(2)s to create a child process; the child inherits a duplicate set of file descriptors that refer to the same pipe. After the fork(2), each process closes the descriptors that it doesn’t need for the pipe (see pipe(7)). The parent then writes the string con‐tained in the program’s command-line argument to the pipe, and the child reads this string a byte at a time from the pipe and echoes it on standard output.
#include <sys/wait.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> int main(int argc, char *argv[]) { int pipefd; pid_t cpid; char buf; if (argc != 2) { fprintf(stderr, "Usage: %s <string>\n", argv); exit(EXIT_FAILURE); } if (pipe(pipefd) == -1) { perror("pipe"); exit(EXIT_FAILURE); } cpid = fork(); if (cpid == -1) { perror("fork"); exit(EXIT_FAILURE); } cpid = fork(); if (cpid == -1) { perror("fork"); exit(EXIT_FAILURE); } if (cpid == 0) { /* Child reads from pipe */ close(pipefd); /* Close unused write end */ while (read(pipefd, &buf, 1) > 0) write(STDOUT_FILENO, &buf, 1); write(STDOUT_FILENO, "\n", 1); close(pipefd); _exit(EXIT_SUCCESS); } else { /* Parent writes argv to pipe */ close(pipefd); /* Close unused read end */ write(pipefd, argv, strlen(argv)); close(pipefd); /* Reader will see EOF */ wait(NULL); /* Wait for child */ exit(EXIT_SUCCESS); } }- open, creat - open and possibly create a file or device
@ man 2 open
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode); int creat(const char *pathname, mode_t mode);Given a pathname for a file,
open()returns a file descriptor, a small, nonnegative integer for use in subsequent system calls. The file descriptor returned by a successful call will be the lowest-numbered file descriptor not currently open for the process.By default, the new file descriptor is set to remain open across an execve(2) (i.e., the FD_CLOEXEC file descriptor flag described in fcntl(2) is initially disabled; the O_CLOEXEC flag, described below, can be used to change this default). The file offset is set to the beginning of the file (see lseek(2)).
A call to open() creates a new open file description, an entry in the system-wide table of open files. This entry records the file offset and the file sta‐tus flags (modifiable via the fcntl(2) F_SETFL operation). A file descriptor is a reference to one of these entries; this reference is unaffected if path‐name is subsequently removed or modified to refer to a different file. The new open file description is initially not shared with any other process, but sharing may arise via fork(2).
The argument flags must include one of the following access modes:
O_RDONLY,O_WRONLY, orO_RDWR. These request opening the file read-only, write-only, or read/write, respectively.In addition, zero or more file creation flags and file status flags can be bitwise-or’d in flags. The file creation flags are O_CLOEXEC, O_CREAT, O_DIRECTORY, O_EXCL, O_NOCTTY, O_NOFOLLOW, O_TRUNC, and O_TTY_INIT. The file status flags are all of the remaining flags listed below. The distinction between these two groups of flags is that the file status flags can be retrieved and (in some cases) modified using fcntl(2).
- close - close a file descriptor
@ man 2 close
#include <unistd.h> int close(int fd);close() closes a file descriptor, so that it no longer refers to any file and may be reused. Any record locks (see fcntl(2)) held on the file it was asso‐ciated with, and owned by the process, are removed (regardless of the file descriptor that was used to obtain the lock).
If fd is the last file descriptor referring to the underlying open file description (see open(2)), the resources associated with the open file description are freed; if the descriptor was the last reference to a file which has been removed using unlink(2) the file is deleted.
Not checking the return value of close() is a common but nevertheless serious programming error. It is quite possible that errors on a previous write(2) operation are first reported at the final close(). Not checking the return value when closing the file may lead to silent loss of data. This can espe‐cially be observed with NFS and with disk quota.
A successful close does not guarantee that the data has been successfully saved to disk, as the kernel defers writes. It is not common for a filesystem to flush the buffers when the stream is closed. If you need to be sure that the data is physically stored use fsync(2). (It will depend on the disk hardware at this point.)
It is probably unwise to close file descriptors while they may be in use by system calls in other threads in the same process. Since a file descriptor may be reused, there are some obscure race conditions that may cause unintended side effects.
- fork - create a child process
- 有病治病,没病强身
- 为什么函数调用要用栈实现?
@ 函数调用通常过程是:
- 1,准备参数(计算参数,传参)
- 2,保存返回地址
- 3,控制转移至 callee
- 4,保存必要的 caller 现场
以上一些步骤之间的顺序是可变的,但理论上并没有哪个步骤是必须用栈来实现的
理论上如果有很多寄存器,我们完全可以抛弃栈,然而实际上我们并没有所以从现实的角度来说,栈是一个适合的实现方法
“调用栈”(call stack)既可以指具体实现,也可以指一种抽象概念—— 由“栈帧”(stack frame)或者叫“活动记录”(activation record)构成的栈。
函数调用的局部状态之所以用栈来记录是因为这些数据的存活时间满足“后入先出”(LIFO)顺序,而栈的基本操作正好就是支持这种顺序的访问。
举例说,假如有下面程序:
void a(); int main() { a(); return 0; } void c() { } void b() { c(); } void a() { b(); }那么整个程序的函数活动时间可以表示为:
main() a() b() c() - main() | +> - a() . | . +> - b() . . | . . +> - c() . . . | . . + <- return from c() . . | . + <- return from b() . | + <- return from a() | - return from main()可以看到,函数的调用有完美的嵌套关系——调用者的生命期总是长于被调用者的生命期,并且后者在前者的之内。
这样,被调用者的局部信息所占空间的分配总是后于调用者的(后入),而其释放则总是先于调用者的(先出),所以正好可以满足栈的 LIFO 顺序,选用栈这种数据结构来实现调用栈是一种很自然的选择。
扩展:顺着 SICP 的线索学下去可以看到函数调用的顺序虽然跟 LIFO 顺序一致,但是调用者的栈帧并不一定要保留,在特殊情况下可以不保留调用者栈帧——尾调用(tail call)的情况。关键点在于调用者是否在一个函数调用之后还有待执行的计算。如果没有了(这个函数调用是尾调用),那调用者的局部状态就没有必要保留。
栈在这里可以有俩个理解,
- 是数据结构栈, 从这个角度说, 是的, 函数调用基本都是使用栈, 原因就是函数调用的 LIFO 特性, 你不用栈可以么, 当然可以, 你可以用 list, 但用栈实现代价最小. 所以 … 这个上面的很多人也回答了.
- 是绝大多数现代操作系统提供的栈 (内存布局), 然而如果从这个角度来说, 那并不是所有的函数调用都是使用它, 比如现在有的 stackless language. 包括 PHP 也是自己申请堆内存来实现函数调用层级关系, 但本质上他们只是没有使用操作系统提供的“栈”, 而自己在堆上申请内存, 实现数据结构的“栈”来完成函数调用, 这样能避免操作系统提供的栈有大小限制 (ulimit -s), 比如我们经常会看到的 stack overflow (这里不仅仅是指上千的嵌套调用), 方便实现同时有成百上千个子任务存在的语言.
refs and see also
- 为什么函数调用要用栈实现?
- 为什么用 od 命令查看 Java 字节码不是大端存储?
@ I love Macross Delta.
大端解释的话结果就跟原本的顺序一样。小端解释则是:
I evol ssorcaM atleD.
而不是整个字符顺序反转:
.atleD ssorcaM evol I
我感觉 RefNaxelaFX 的解释错了。小端应该是
Delta. Macross love I
外,刚写了这个程序,贴在这里:
// 思想来自 Programming Pearls #include <stdio.h> #include <string.h> void reverse( char *s, int left, int right ) { char tmp; while( left < right ) { tmp = s[left]; s[left] = s[right]; s[right] = tmp; ++left; --right; } } void solve( char *s ) { int left = 0, right = 0, len = strlen(s); while( left < len && right < len ) { while( s[right] && s[right] != ' ' ) { ++right; } if( !s[right] && left < right-1 ) { reverse( s, left, right-1 ); // 最后一段 break; } reverse( s, left, right-1 ); left = right + 1; // 跳过连续空格 while( s[left] == ' ' ) { ++left; } right = left + 1; } reverse( s, 0, len-1 ); // 这个 len-1 千万不能是 len } int main() { char buf; sprintf( buf, "%s", "I love Sia Furler." ); printf( "before: %s\n", buf ); solve( buf ); printf( "%s\n", buf ); }
refs and see also
- 为什么用 od 命令查看 Java 字节码不是大端存储?
- 堆、栈的地址高低? 栈的增长方向?
@ 进程地址空间的分布取决于操作系统,栈向什么方向增长取决于操作系统与 CPU 的组合。不要把别的操作系统的实现方式套用到 Windows 上。
x86 硬件直接支持的栈确实是“向下增长”的:push 指令导致 sp 自减一个 slot, pop 指令导致 sp 自增一个 slot。其它硬件有其它硬件的情况。
- sp: stack pointer, see Understanding the Stack

refs and see also
- 栈的增长方向与栈帧布局
这个上下文里说的“栈”是函数调用栈,是以“栈帧”(stack frame)为单位的。每一次函数调用会在栈上分配一个新的栈帧,在这次函数调用结束时释放其空间。被调用函数(callee)的栈帧相对调用函数(caller)的栈帧的位置反映了栈的增长方向:如果被调用函数的栈帧比调用函数的在更低的地址,那么栈就是向下增长;反之则是向上增长。
而在一个栈帧内,局部变量是如何分布到栈帧里的(所谓栈帧布局,stack frame layout),这完全是编译器的自由。至于数组元素与栈的增长方向:C 与 C++ 语言规范都规定了数组元素是分布在连续递增的地址上的。
C 与 C++ 语言的数组元素要分配在连续递增的地址上,也不反映栈的增长方向。
- 以简化的 Linux/x86 模型为例
在简化的 32 位 Linux/x86 进程地址空间模型里,(主线程的)栈空间确实比堆空间的地址要高——它已经占据了用户态地址空间的最高可分配的区域,并且向下(向低地址)增长。
Tim Chen
- 堆没有方向之说,每个堆都是散落的
- 堆和栈之间没有谁地址高之说,看操作系统实现
- 数组取下标偏移总是往上涨的,和在堆还是栈没啥关系
refs and see also
- 堆、栈的地址高低? 栈的增长方向?
- 字符编码笔记:ASCII,Unicode 和 UTF-8 - 阮一峰的网络日志
@ ASCII, 0–127

Non-ASCII
130 在法语编码中代表了 é,在希伯来语编码中却代表了字母 Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0–127 表示的符号是一样的,不一样的只是 128–255 的这一段。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是 GB 类的汉字编码与后文的 Unicode 和 UTF-8 是毫无关系的。
Unicode
Unicode 当然是一个很大的集合,现在的规模可以容纳 100 多万 (1 million, 2^20 = (23)(20/3) = 6 bytes) 个符号。每个符号的编码都不一样,比如,U+0639 表示阿拉伯字母 Ain,U+0041 表示英语的大写字母 A, U+4E25 表示汉字“严”。具体的符号对应表,可以查询 unicode.org,或者专门的汉字对应表。
UTF-8
UTF-8 是 Unicode 的实现方式之一。UTF-8,UTF-16,UTF-32,etc。
Unicode Range | UTF-8 Encoding Hex | Binary --------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 110x -> 1100(12)/1101(13) -> C/E 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx7F -> 7FF -> FFFF, (1/2/4 F's)很简单,第一个字节
0 开头的就是一个 ASCII 字符,0 前面有两个 1(即“110”)则为两个字节的非 ASCII,三个 1,则三个字节的非 ASCII;四个则为四个字节的非 ASCII。
第二个字节
不是 ASCII,所以不是 0 开头。都以 10 开头。
不过阮一峰表达得很简洁!:
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是 0,则这个字节单独就是一个字符;如果第一位是 1,则连续有多少个 1,就表示当前字符占用多少个字节。
已知“严”的 unicode 是 4E25(100111000100101),根据上表,可以发现 4E25 处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的 UTF-8 编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的 x,多出的位补 0。这样就得到了,“严”的 UTF-8 编码是 “11100100 10111000 10100101”,转换成十六进制就是 E4B8A5。
在 vim 中
g8查看 utf-8 编码,发现“严”是e4 b8 a5,用ga查看 unicode,还会输出 Dec 值、Hex 值和 Octal 值。Little endian 和 Big endian
以汉字“严”为例,Unicode 码是 4E25,需要用两个字节存储,一个字节是 4E,另一个字节是 25。存储的时候,4E 在前,25 在后,就是 Big endian 方式;25 在前, 4E 在后,就是 Little endian 方式。
Unicode 规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做“零宽度非换行空格”(ZERO WIDTH NO-BREAK SPACE),用 FEFF 表示。这正好是两个字节,而且 FF 比 FE 大 1。(增->大端,减->小端)
Byte Order Mark: BOM
The UTF-8 representation of the BOM is the byte sequence
0xEF,0xBB,0xBF.- UTF-8 without BOM
The Internationally defined Standard ISO/IEC 10646, Universal Character Set (UCS) know as UTF-8 (Universal Character Set + Transformation Format—8-bit) is a variable-width encoding that can represent every character in the Unicode character set. It was designed for backward compatibility(后向兼容) with ASCII and to avoid the complications( 并发症) of endianness(字节顺序) and byte order marks in UTF-16 and UTF-32.
UTF-8 has become the dominant character encoding for the World Wide Web, accounting for more than half of all Web pages. The Internet Mail Consortium (IMC) recommends that all e-mail programs be able to display and create mail using UTF-8. The W3C recommends UTF-8 as default encoding in their main standards (XML and HTML).
The official IANA code for the UTF-8 character encoding is UTF-8.
The
UTF-8 BOMis a sequence of bytes (EF BB BF) that allows the reader to identify the file as an UTF-8 file.Normally, the BOM is used to signal the endianness of the encoding, but since endianness is irrelevant to UTF-8, the BOM is unnecessary.
According to the Unicode standard, the BOM for UTF-8 files is not recommended.
the International Organization for Standardization(ISO)the International Electrotechnical Commission(IEC)Byte Order Mark(BOM)Internet Assigned Numbers Authority(IANA) 互联网号码分配局
- Endianess
@ 

Big-endian is the most common format in data networking; fields in the protocols of the Internet protocol suite, such as IPv4, IPv6, TCP, and UDP, are transmitted in big-endian order. For this reason, big-endian byte order is also referred to as network byte order. Little-endian storage is popular for microprocessors, in part due to significant influence on microprocessor designs by Intel Corporation. Mixed forms also exist, for instance the ordering of bytes in a 16-bit word may differ from the ordering of 16-bit words within a 32-bit word. Such cases are sometimes referred to as mixed-endian or middle-endian. There are also some bi-endian processors that operate in either little-endian or big-endian mode.
refs and see also
- 字符编码笔记:ASCII,Unicode 和 UTF-8 - 阮一峰的网络日志
- RapidJSON 代码剖析(三):Unicode 的编码与解码 - Milo 的编程
@ UTF-8 成为现时互联网上最流行的格式,有几个原因:
- 它采用字节为编码单元,不会有字节序(endianness)的问题。
- 每个 ASCII 字符只需一个字节去储存。
- 如果程序原来是以字节方式储存字符,理论上不需要特别改动就能处理 UTF-8 的数据。
RapidJSON 希望尽量支持各种常用 UTF 编码,用四百多行代码实现了 5 种 Unicode 编码器/解码器,另外加上 ASCII 编码。本文会简单介绍它的实现方式。
rapidjson/encodings.h at master · miloyip/rapidjson
refs and see also
- RapidJSON 代码剖析(三):Unicode 的编码与解码 - Milo 的编程
- Hamming weight
@ 说一个故事,四五年前我为面试出了一条笔试题目,恰巧和本书的题目 2.1 很相似,计算一个无号整数 (我要求 32-bit,书中的是 8-bit) 在二进制中 1 的个数。当时心想这个题目很简单吧,谁知有些应征者在这题上交白卷,更难找到一些能写到更优化答案的人了,并以为自己做出的解法已经是最优。不过,几年后,我才知道原来这个问题是有正式的学名,叫 Hamming Weight,除了有更快的算法外,在 SIMD 4.2 也有指令去计算。当时就为自己的无知感到惭愧。
The Hamming weight of a string is the number of symbols that are different from the zero-symbol of the alphabet used. It is thus equivalent to the Hamming distance from the all-zero string of the same length. For the most typical case, a string of bits, this is the number of 1’s in the string. In this binary case, it is also called the population count, popcount, or sideways sum. It is the digit sum of the binary representation of a given number and the ℓ₁ norm of a bit vector.
string Hamming weight 11101 4 11101000 4 00000000 0 789012340567 10 The population count of a bitstring is often needed in cryptography and other applications. The Hamming distance of two words A and B can be calculated as the Hamming weight of A xor B.
The problem of how to implement it efficiently has been widely studied. Some processors have a single command to calculate it (see below), and some have parallel operations on bit vectors. For processors lacking those features, the best solutions known are based on adding counts in a tree pattern. For example, to count the number of 1 bits in the 16-bit binary number a =
0110 1100 1011 1010, these operations can be done:
Here, the operations are as in C, so
X >> Ymeans to shift X right by Y bits,X & Ymeans the bitwise AND of X and Y, and+is ordinary addition. The best algorithms known for this problem are based on the concept illustrated above and are given here:As Wegner (1960) described, the bitwise and of x with x − 1 differs from x only in zeroing out the least significant nonzero bit: subtracting 1 changes the rightmost string of 0s to 1s, and changes the rightmost 1 to a//types and constants used in the functions below const uint64_t m1 = 0x5555555555555555; //binary: 0101... const uint64_t m2 = 0x3333333333333333; //binary: 00110011.. const uint64_t m4 = 0x0f0f0f0f0f0f0f0f; //binary: 4 zeros, 4 ones ... const uint64_t m8 = 0x00ff00ff00ff00ff; //binary: 8 zeros, 8 ones ... const uint64_t m16 = 0x0000ffff0000ffff; //binary: 16 zeros, 16 ones ... const uint64_t m32 = 0x00000000ffffffff; //binary: 32 zeros, 32 ones const uint64_t hff = 0xffffffffffffffff; //binary: all ones const uint64_t h01 = 0x0101010101010101; //the sum of 256 to the power of 0,1,2,3... //This is a naive implementation, shown for comparison, //and to help in understanding the better functions. //It uses 24 arithmetic operations (shift, add, and). int popcount_1(uint64_t x) { x = (x & m1 ) + ((x >> 1) & m1 ); //put count of each 2 bits into those 2 bits x = (x & m2 ) + ((x >> 2) & m2 ); //put count of each 4 bits into those 4 bits x = (x & m4 ) + ((x >> 4) & m4 ); //put count of each 8 bits into those 8 bits x = (x & m8 ) + ((x >> 8) & m8 ); //put count of each 16 bits into those 16 bits x = (x & m16) + ((x >> 16) & m16); //put count of each 32 bits into those 32 bits x = (x & m32) + ((x >> 32) & m32); //put count of each 64 bits into those 64 bits return x; } //This uses fewer arithmetic operations than any other known //implementation on machines with slow multiplication. //It uses 17 arithmetic operations. int popcount_2(uint64_t x) { x -= (x >> 1) & m1; //put count of each 2 bits into those 2 bits x = (x & m2) + ((x >> 2) & m2); //put count of each 4 bits into those 4 bits x = (x + (x >> 4)) & m4; //put count of each 8 bits into those 8 bits x += x >> 8; //put count of each 16 bits into their lowest 8 bits x += x >> 16; //put count of each 32 bits into their lowest 8 bits x += x >> 32; //put count of each 64 bits into their lowest 8 bits return x & 0x7f; } //This uses fewer arithmetic operations than any other known //implementation on machines with fast multiplication. //It uses 12 arithmetic operations, one of which is a multiply. int popcount_3(uint64_t x) { x -= (x >> 1) & m1; //put count of each 2 bits into those 2 bits x = (x & m2) + ((x >> 2) & m2); //put count of each 4 bits into those 4 bits x = (x + (x >> 4)) & m4; //put count of each 8 bits into those 8 bits return (x * h01)>>56; //returns left 8 bits of x + (x<<8) + (x<<16) + (x<<24) + ... }- If x originally had n bits that were 1, then after only n iterations of this operation, x will be reduced to zero. The following implementation is based on this principle.
//This is better when most bits in x are 0 //It uses 3 arithmetic operations and one comparison/branch per "1" bit in x. int popcount_4(uint64_t x) { int count; for (count=0; x; count++) x &= x-1; return count; }- 我的测试
@ - 代码
#include <stdio.h> int popcount_4(int x) { int count; for (count=0; x; count++) x &= x-1; return count; } int main(int argc, char **argv) { int i = 0; scanf("%d", &i); do { printf("%d has %d '1's.\n", i, popcount_4(i)); } while( 1 == scanf("%d", &i) ); return 0; }- 编译运行
$ gcc main.c -o main.exe $ echo 1 2 3 4 5 8 24 235265 | ./main.exe 1 has 1 '1's. 2 has 1 '1's. 3 has 2 '1's. 4 has 1 '1's. 5 has 2 '1's. 8 has 1 '1's. 24 has 2 '1's. 235265 has 8 '1's.
If we are allowed greater memory usage, we can calculate the Hamming weight faster than the above methods. With unlimited memory, we could simply create a large lookup table of the Hamming weight of every 64 bit integer. If we can store a lookup table of the hamming function of every 16 bit integer, we can do the following to compute the Hamming weight of every 32 bit integer.
static uint8_t wordbits = { /* bitcounts of integers 0 through 65535, inclusive */ }; static int popcount(uint32_t i) { return (wordbits[i&0xFFFF] + wordbits[i>>16]); }refs and see also
- Hamming weight
- Dynamic cast
@ // static_cast_Operator.cpp // compile with: /LD class B {}; class D : public B {}; void f(B* pb, D* pd) { D* pd2 = static_cast<D*>(pb); // Not safe, D can have fields // and methods that are not in B. B* pb2 = static_cast<B*>(pd); // Safe conversion, D always // contains all of B. } // static_cast_Operator_2.cpp // compile with: /LD /GR class B { public: virtual void Test(){} }; class D : public B {}; void f(B* pb) { D* pd1 = dynamic_cast<D*>(pb); D* pd2 = static_cast<D*>(pb); } // static_cast_Operator_3.cpp // compile with: /LD /GR typedef unsigned char BYTE; void f() { char ch; int i = 65; float f = 2.5; double dbl; ch = static_cast<char>(i); // int to char dbl = static_cast<double>(f); // float to double i = static_cast<BYTE>(ch); } // dynamic_cast_1.cpp // compile with: /c class B { }; class C : public B { }; class D : public C { }; void f(D* pd) { C* pc = dynamic_cast<C*>(pd); // ok: C is a direct base class // pc points to C subobject of pd B* pb = dynamic_cast<B*>(pd); // ok: B is an indirect base class // pb points to B subobject of pd } // dynamic_cast_2.cpp // compile with: /c /GR class A {virtual void f();}; class B {virtual void f();}; void f() { A* pa = new A; B* pb = new B; void* pv = dynamic_cast<void*>(pa); // pv now points to an object of type A pv = dynamic_cast<void*>(pb); // pv now points to an object of type B } // dynamic_cast_3.cpp // compile with: /c /GR class B {virtual void f();}; class D : public B {virtual void f();}; void f() { B* pb = new D; // unclear but ok B* pb2 = new B; D* pd = dynamic_cast<D*>(pb); // ok: pb actually points to a D D* pd2 = dynamic_cast<D*>(pb2); // pb2 points to a B not a D }a
type qualifieris not allowed on a static member function.
- Dynamic cast
- Good Old & Dirty printf() Debugging in a Non-console C/C++ Application or DLL
@ #define Debug(fmtstr, ...) printf(fmtstr, ##__VA_ARGS__)http://www.cnblogs.com/xianqingzh/archive/2011/07/08/2101510.html
- 《Debug Hacks》和调试技巧 | MaskRay
@ freopen// like piping freopen(in_path, "r", stdin); freopen(out_path, "w", stdout); freopen(err_path, "w", stderr); // remember to close them: fclose(stdin); fclose(stdout); fclose(stderr);Debugging PRINT
#ifdef _DEBUG # define Debug(fmtstr, ...) printf(fmtstr, ##__VA_ARGS__) #else # define Debug(fmtstr, ...) #endif这是
__VAR_ARGS__,就连 Windows 也支持。还可参考:C is awesome – function pointer stack
VARS
ANSI C 标准中有几个标准预定义宏(也是常用的):
__LINE__:在源代码中插入当前源代码行号;__FILE__:在源文件中插入当前源文件名;__DATE__:在源文件中插入当前的编译日期__TIME__:在源文件中插入当前编译时间;__STDC__:当要求程序严格遵循ANSI C标准时该标识被赋值为1;__cplusplus:当编写C++程序时该标识符被定义。
#define KEYWORD还是#define KEY VALUE?有人喜欢这样:
#define DEBUG // 此时 #ifdef DEBUG 为真 //#define DEBUG 0 // 此时为假 int main() { #ifdef DEBUG printf("Debugging\n"); #else printf("Not debugging\n"); #endif printf("Running\n"); return 0; }不过我更喜欢这样:
#define BEDUG (true) if (debug) { // todo }当然前者编出的程序性能会好一点。
- return 的妙用
这个主要用于 test,比如:
// define some testing vars here // this is test6 (current testing part) return; // this is test5 return; // this is test4 ... return; // test0好处是不用总去注释,坏处是编出来的程序会大一点,还可能忘了把 return 去掉,导致提前退出而不自知。
- Windows 编译宏:Predefined Macros (C/C++)
这个好,可以用:
_WIN64- C
这个我比较熟悉,如果你能看懂下面这些就够了:
// printf %i %d %lld (for long long int/size_t, int64_t) %20d (width at %least 20 char) %020d (preceeding zero's) %-20d (left align) %%+20d (explicit positive sign) %f %lf (double) %5.2lf %s %-s %20s %*d %*s ("%*s", 5, " "), five spaces // scanf %*d %*s %lf, ignore int/string/double不举例子了
就像 C++ 中的 StringStream
```cpp QString result; QTextStream(&result) << “pi =” << 3.14; // result == “pi = 3.14”
- 《Debug Hacks》和调试技巧 | MaskRay
refs and see also
- Good Old & Dirty printf() Debugging in a Non-console C/C++ Application or DLL
- Jeff Dean facts: How a Google programmer became the Chuck Norris of the Internet
@ 32,768,65,536,4,294,967,296- If you could harness the power of the multiverse you could try every possible option in the design space and see which worked best. But that’s crazy impractical, isn’t it?
- Dr. Dean thinks an important skill for every software engineer is the ability to estimate the performance of alternative systems, using back of the envelope calculations, without having to build them.
Numbers Everyone Should Know
To evaluate design alternatives you first need a good sense of how long typical operations will take. Dr. Dean gives this list:
- L1 cache reference 0.5 ns
- Branch mispredict 5 ns
- L2 cache reference 7 ns
- Mutex lock/unlock 100 ns
- Main memory reference 100 ns
- Compress 1K bytes with Zippy 10,000 ns
- Send 2K bytes over 1 Gbps network 20,000 ns
- Read 1 MB sequentially from memory 250,000 ns
- Round trip within same datacenter 500,000 ns
- Disk seek 10,000,000 ns
- Read 1 MB sequentially from network 10,000,000 ns
- Read 1 MB sequentially from disk 30,000,000 ns
- Send packet CA->Netherlands->CA 150,000,000 ns
Some things to notice:
- Notice the magnitude differences in the performance of different options.
- Datacenters are far away so it takes a long time to send anything between them.
- Memory is fast and disks are slow.
- By using a cheap compression algorithm a lot (by a factor of 2) of network bandwidth can be saved.
- Writes are 40 times more expensive than reads.
- Global shared data is expensive. This is a fundamental limitation of distributed systems. The lock contention in shared heavily written objects kills performance as transactions become serialized and slow.
- Architect for scaling writes.
- Optimize for low write contention.
- Optimize wide. Make writes as parallel as you can.
Lessons Learned
- Back-of-the-envelope calculations allow you to take a look at different variations.
- When designing your system, these are the kind of calculations you should be doing over and over in your head.
- Know the back of the envelope numbers for the building blocks of your system. It’s not good enough to just know the generic performance numbers, you have to know how your subsystems perform. You can’t make decent back-of-the-envelope calculations if you don’t know what’s going on.
- Monitor and measure every part of your system so you can make these sorts of projections from real data.
refs and see also
用二进制可以快速地估算,下面是一些常用数字:
Hex Bin 1000 ≈ 210, 29.9 100 26.6, 6.6666666666666666666 10 23.3, 3.333333333333333333 e = 2.72 21.44 (272=256, 256/100 = 28/26.66 = 21.44) 3 21.6 pi = 3.14 21.65, pi2 = 9 = 10 = 23.3, so pi = 21.65 12 23.6 (3*4 = 21.6+2) 24 24.6 (3*8) 48 25.6 (3*16) 96 26.6 (3*32) 60 25.9 (64 = 26, 60=6*10=22.6+3.3) 360 28.5 (360 = 60*60/10 = 211.8=5.9+5.9/23.3 = 28.5) 3600 211.8 (6060 = 2^^5.92^^), 4096 = 212 地球半径 R = 6371 km = 6371 × 103 m 222.6 = 2626.6210 = 222.6=(6+6.6+10) 怎么用,举例:
比如你想知道赤道上一个经度对应的长度,
地球半径为 \(R\) = 6371 千米 = 2 22.6 m,则 distance = \(\frac{2\pi \times R}{360}\) = 2(1+1.651+22.6-8.5) = 210+6.75 = 1000 * 100 = 100 km。和实际用计算器计算的 110 km 差不多。
一天的秒数?606024 = (2323100)38 = 22×(1+1.6)+6.6+1.6+3 = 25.2+6.6+1.6+3 = 210.4+3 = 216.4,显然这么分解效率太低,所以我们用上 3600 和 24,3600×24 = 211.8+4.6 = 216.4,这么算,效率就高了。
你也看到我们需要反向计算 2x 的十进制是多少,所以再列一个表:
Bin Hex 21 2 22 4 23 8 24 16 25 32 26 64 27 128 28 256 29 512 = 500 210 1024 = 1000 211 2048 212 4096 213 8192 214 16384 215 = 210 * 25 1000 x 32 = 32 k (实际为 32768) 216 65536 231 1k x 1k * 1k x 2 = 1m x 1k x 2 = 1g x 2 = 2g(2 billion) (实际为 2,147,483,648) 1 232 4g, 4,294,967,296 - k: thousand
- m: million
- g: billion
Value SI2 210 = 1000 k 220 = 10002 M 230 = 10003 G 240 = 10004 T 250 = 10005 P 260 = 10006 E 270 = 10007 Z 280 = 10008 Y Value IEC3 JEDEC 210 = 1024 Ki kibi 220 = 10242 Mi mebi 230 = 10243 Gi gibi 240 = 10244 Ti tebi 250 = 10245 Pi pebi 260 = 10246 Ei exbi 270 = 10247 Zi zebi 280 = 10248 Yi yobi +-----------+ | 8421 | | xxxx | +-----------+ 0000 -> 0 0001 -> 1 0010 -> 2 0011 -> 3 = 2+1 0100 -> 4 0101 -> 5 = 4+1 0110 -> 6 = 4+2 0111 -> 7 = 4+2+1 1000 -> 8 1001 -> 9 = 8+1 1010 -> a = 8+2 = 10 1011 -> b = 8+2+1 = 11 12345 -> bcdef, b1 c2 d3 c4 f5 1100 -> c = 8+4 = 12 [a: 10], [c: 12], [f: 15] 1101 -> d = 8+4+1 = 13 1110 -> e = 8+4+2 = 14 1111 -> f = 8+4+2+1 = 15 +---------------------------+ | | | 1 a 14 n | | 2 b 15 o | | 3 c 16 p | | 4 d 17 q | | 5 e 18 r | | 6 f 19 s | | | | 7 g 20 t | | | | 8 h 21 u | | 9 i 22 v | | 10 j 23 w | | 11 k 24 x | | 12 l 25 y | | 13 m 26 z | | | +---------------------------+常见质数以及其它:
Num Binary 2 21 3 21.6 5 22.3, 512/100 = 29/26.666666666666 = 22.3 7 22.8 11 23.5 13 23.7 1001 = 7 * 11 * 13 2^10 = 2^2.8 * 2^3.5 * 2^3.7 10 = 2.8 + 3.5 + 3.7refs and see also
- Jeff Dean facts: How a Google programmer became the Chuck Norris of the Internet
- 估算法
@ - 斯特林公式,Stirling’s approximation / Stirling’s formula
@ 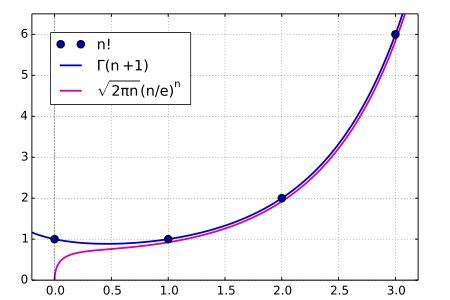
Comparison of Stirling’s approximation with the factorial
Time value of money - Wikipedia, the free encyclopedia
Method of matched asymptotic expansions - Wikipedia, the free encyclopedia

A tiling with squares whose side lengths are successive Fibonacci numbers
refs and see also
- 斯特林公式,Stirling’s approximation / Stirling’s formula



- malloc 与 free? - 知乎
@ 我先问你个问题:指针中是没有所在内存块大小的信息的,那么 free 怎么才能知道要释放的内存块有多大呢?于是,对于大多数内存分配器,malloc 申请的实际内存比你要求的空间要大几个字节,里面存储了额外的数据来记录这块内存有多大,一般就是直接存在指针左边。free 的时候,就会去读取指针地址减去一个常数之后的那块内存,来获取内存块的信息。因此如果你 free 一个不指向内存块开始处的指针,free 的时候就会把其他的数据错误解释成内存块的信息,(大概率)导致程序崩溃。当然现代的内存分配器对于不同大小的内存申请,会采用不同的分配策略,但无论策略如何,去 free 一个不是 malloc 来的指针,都是非常危险的举动。
作者:Belleve
初学者的话,不要多想,把 CSAPP 看了再说。
C 是一门<设计感不是很强的语言>,换句话说很多东西就是没什么道理和规律可循的,要知道具体的问题和当时的写法才能明白其中道理。
比如吧,malloc 是个内存管理 package,并不是一个很底层的东西。 更加底层的看,一个程序有一大块内存,叫作 heap。但是呢,heap 的大小是有限的,用完了问操作系统要更多 heap,是很耗费资源的,于是就需要内存管理系统来帮助整理 heap,提高利用率。
这个时候就要在内存里面建立一个链表,把没有用的内存块,大小等等都储存起来,方便按照大小取用。随着内存块被 malloc 和被 free,这些 free block 也会被打散和合并。之所以可以做到,就是因为默认每个内存块的首尾都记录有信息。
你任意在内存块里移动,free 的时候程序自动往前读一个 block,发现的却不是一个完整的 tag (你自己放了什么就是什么),assertion failure 已经是小事了,基本上会 segfault,运气不好你会跳到别的内存块去,损坏一大片内存。
所以,不要乱搞。CSAPP 里自己写过一个 malloc 就明白了。
当然了,国内一般是不教 Linux 和 bash 一类的,国内很多人是不会用的,这也是为啥大家都觉得 windows 好的一个原因。我可以负责任地说我在美国读的 CS 本科,系里没有一台 Windows 电脑。
电池是化学工业。
新材料的研发难度是知乎这群程序员根本无法想象的。程序员们都活在完美的无熵世界里,邱奇和图灵命定了整个世界的法则。律法是存在的,而且是万能的,我们只需要跟从律法,就能得到想要的结果——如果它不对,一定是我的问题,找到改正就好。醒醒吧,真实世界远远比你们的小世界可怕,我们面对的是一片漆黑和死寂,我们不知道规则,不知道哪里是致命的陷阱:做材料研究的是在和上帝搏斗。
做个不恰当的比喻:研发新材料的难度好比 @李阿玲 徒手写 TeX:一次写出一个四万行的程序,各个部件耦合性极强且无法解耦,写完前无法预测结果,无法单元测试…… 啊不对,材料研究比 @李阿玲 更加令人绝望,因为 @李阿玲 好歹可以去 debug,材料的性质不对无法 debug,只能改配方重新合成一份来 trial-and-error (
['traɪəl]),错了不知道为什么,最后成功了也不知道为什么……因此真无怪乎有些人把材料科学比作「往下水道扔钱」。有人问计算化学——很好,我们组就是做计算化学的,优化一个 30 原子的小分子结构需要两个小时;预测两个小分子的反应产物需要整整一天。我不认为地球上有一台超算能在人类可接受的时间内算出某个电池结构的电量。refs and see also
- malloc 与 free? - 知乎
- deerchao的个人网站
@ `^\w+` 匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置) `<a[^>]+>` 匹配用尖括号括起来的以a开头的字符串。 `(?=exp)` 也叫**零宽度正预测先行断言**,它断言自身出现的位置的后面能匹配表 达式exp。比如 `\b\w+(?=ing\b)`,匹配以 ing 结尾的单词的前面部分(除了ing以外 的部分),如查找 `I'm singing while you're dancing.` 时,它会匹配sing和danc。 (?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。 比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在 查找reading a book时,它匹配ading。 地球人,是不是觉得这些术语名称太复杂,太难记了?我也有同感。知道有这么一种 东西就行了,它叫什么,随它去吧!人若无名,便可专心练剑;物若无名,便可随意 取舍…… 断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹 配。 负向零宽断言 例如:\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b 匹配不包含连续字符串abc的单词。 为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说 ,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有 最高的优先权——The match that begins earliest wins。平衡组/递归匹配
- url:
[a-zA-z]+://[^\s]* - qq:
[1-9]\d{4,} - htlm tag:
<(.*)(.*)>.*<\/\1>|<(.*) \/> - chinese:
[\u4e00-\u9fa5] - chinese chars and puncs:
[\u3000-\u301e\ufe10-\ufe19\ufe30-\ufe44\ufe50-\ufe6b\uff01-\uffee] - chinese id card:
\d{15}(\d\d[0-9xX])?
refs and see also
- url:
- deerchao的个人网站
- Shell, Terminal, Console 区别 - 為學日益, 為道日損
@ - shell is script translator
- terminal is the app that wrap a shell
- console is…, what the fuck it is?

- Shell, Terminal, Console 区别 - 為學日益, 為道日損
airplane rule@simplicity incerase robustness.
Complexity increases the possibility of failure; a twin-engine airplane has twice as many engine problems as a single-engine airplane
By analogy, in both software and electronics, the rule that simplicity increases robustness.
It is correspondingly argued that the right way to build reliable systems is to put all your eggs in one basket, after making sure that you’ve built a really good basket.
unzip@c, compress; x, extract, f, file
- .zip (
zip & unzip) zip -r archive_name.zip directory_to_compress # r: recursive unzip archive_name.zip- .tar (
{c/x}vf) tar -cvf archive_name.tar directory_to_compress tar -xvf archive_name.tar.gz tar -xvf archive_name.tar -C /tmp/extract_here/ # C: change outdir- .tar.gz (
.tar + z) tar -zcvf archive_name.tar.gz directory_to_compress tar -zxvf archive_name.tar.gz tar -zxvf archive_name.tar.gz -C /tmp/extract_here/- .tar.bz2 (
.tar + j) tar -jcvf archive_name.tar.bz2 directory_to_compress tar -jxvf archive_name.tar.bz2 -C /tmp/extract_here/- .tar.xz (
.tar + x) tar xvfJ filename.tar.xz tar xpvf /path/to/my_archive.tar.xz -C /path/to/extract tar --xz -xvf filename.tar.xz
refs and see also
- .zip (
- 灵魂机器 答过的问题 - 知乎
@ 所以,你自己在提这个问题之前,其实已经知道了答案,就不妨明说吧,你在二本学校,进 google 的可能性有,但是概率非常非常非常低,比其他学校的学生概率要低得多。如果你在大学四年,不玩命学习,每天学习时间不超过 11 小时(类似于武侠小说的主角,基本都有一段奇遇,经历过后功力大涨),你就洗洗睡吧。
首先最基本的两点建议,
- 无论白天黑夜,不要带手机在身边,每天只在睡觉前把手机打开 15 分钟,处理未接电话和未读短信,最好是把手机砸了(作为学生社交关系非常简单,完全没必要拥有手机)
- 打开电脑除了 Google, Stackoverflow 等编程网站,不要上其他社交网站,例如 QQ,微博等等,禁止开机进入 Windows, 装个 Ubuntu.
2015/02/18日更新:
不少人觉得这方法很偏激,我才说了两点建议。。。我不妨说的更具体一点,说说我当年是如何操作的吧
- 戒手机。每天只在 23:30 睡觉前开机手法短信,回几个电话,当然,随着与世隔绝的日子一天一天下去,我的未接短信和未接电话越来越少,几个月后只有几个亲人偶尔有联系。
- 戒网。比前面的建议更激进,基本一个月只上一次网,每次上网也是查查信息。
- 戒电脑。我认为大部分人打开电脑后,注意力会涣散,一会儿就偏离开机前心里想要做的事,四处看网页去了,于是我一狠心让自己每天只用一个小时电脑。
- 由于戒了电脑,我只能在纸上写代码。我一般会花几个小时,写上十几页的代码,然后用一个小时,把代码敲进去,编译运行。这锻炼了我一次性写出 bug free 代码的能力,后来一部分代码还行形成了一本开源书, soulmachine/acm-cheat-sheet · GitHub
- 由于戒了电脑,没有 evernote 做笔记了, 我便用纸和笔记笔记,用掉了五六个笔记本,每当写满了一百多页后,便集中开电脑几个小时,把笔记敲进电脑。这些笔记后来也形成了一些电子书, / - soulmachine - a brank new AI architecture , 曾经受到很多考研朋友的喜爱。
- 每天学习 11 个小时。很多人觉得 11 个小时没什么,不错,一天两天如此没什么,可是天天如此,就需要对时间安排极度精准了,我的日程是这样的,每天 7:00 起床, 10 分钟吃早餐,10 分钟步行到自习室, 7:30 准时开始看书,11:30 去食堂吃饭, 17:30 吃晚饭, 23:00 下自习,回到租住的房间洗漱睡觉。
有几个 tips 要注意,
- 早餐一定要简单,如果你去食堂吃或者路边买早餐,10 分钟搞定不可能,所以我都是每周末去一次超市,买一袋子面包片,每天早晨两片面包,其他复杂的食物,例如果汁,水煮鸡蛋等都很费时间
- 午睡在桌子上趴着睡就好,回到房间睡床上,一睡就不想起来。
总结,以上所有方法都是围绕一个核心,与世隔绝,极致专注。
再打个比方,不少人说用 Kindle 看书比 iPad Mini 效率高,我估计可能因为 Kindle 干别的都不行,只好专心看书。我使用过两者均长达一年多,亲身体验,确实是这个原因。那这个例子跟本答案有类似之处。如果你想学习,就把自己放到一个除了学习什么都干不了的环境中。
对一个人说的话找错误是非常容易的,如果我把我所说的话,全部在逻辑上修复严密,比如“戒网”改成“在一定程度上戒网”,如此这般把所有文字修改一遍,那这些话就变成了政治正确的完美废话,重要观点就淹没在琐碎冗长的文字之中了。因此,我会直接忽视那些抬杠的,挑小毛病的评论。
作为面试官,我曾经听说过几个面试者对我给他们的面试经历评价为“明明小公司一个,面什么算法”。后来我曾经找出了其中一些人的简历,回忆了一下面试过程,基本上他们都满足以下四条中的两条以上:
- 简历上 4-5 个项目经历,结果一问,别说不是项目主持了,根本就是参与度极低,一问三不知。(我曾遇到过同一个大概不超过 1 万行的项目在 3 个人简历上同时出现的,而且他们都不是项目主持)
- 简历上声称熟练掌握的内容,掌握程度仅限于最基本的使用,缺乏任何的设计分析能力。
- 对所面试的岗位毫无概念,不明白自己是否符合岗位描述上的必要条件
- 对面试提问思路不清晰,或思路表达不清晰。面对问题时,不是仅仅得不到完美的最终答案,而是思路一片空白。
- 坚决认为 C++ 是王道,“我还是想做 C++”,拒绝多语言工作和学习。但实际上 C++ 掌握的并不好。
鄙公司(小公司招人不容易啊!)面试程序时,除非简历上写明了 ACM 获奖经历,否则我给他们安排的所谓“算法题”基本上不会超过二分查找的难度,而且其实并没有太多思路上的扩展,仅仅是算法实现而已。而且这仅限于我实在找不出任何的其它亮点,完全无法满足一个 C++ 岗位的要求,还坚持想从事 C++ 岗位的时候才会进行这样的提问。因为我们其实是相信员工在岗位上的成长的,面试时不允许查找资料,时间也有限,能解决的问题难度不如工作时所能解决的问题难度也是很正常的。但至少你要有点思路吧?二分查找不会写个枚举也好吧?白卷是闹哪样?
结果他们认为是因为算法题表现不好而被我拒绝了。
除了鄙公司,以我在大公司的被面试以及面试经验,虽然连基本的算法题都答不出实在是一件值得鄙视和怀疑的事情,但我依然觉得如果你各方面能力均表现优秀,十分符合岗位所需的要求,其实是不太会因为一个复杂的算法题没有答上来而直接被挂掉的。当然,如果你在面试算法题时毫无思路,或缺乏基本的算法复杂度分析等能力,被扣分也几乎是一定的。你被各方面都不比你差,算法问题表现比你更强的面试者干掉,也是很有可能的。
说了那么多,总结起来只有一句:“因为公司面算法而义愤填膺的,肯定是面试挂掉了而不知道自己究竟为什么挂掉了的。”
我觉得未来的面试都改成综艺节目那种形式,四个人一组,现场用答题板答题,这样被刷掉的就不会有那么多怨言了……
PS: 爱抱怨的还是少数。我遇到的面试者中,还是有不少虽然我没有录取(不符合岗位需求),但性格和沟通上还是很喜欢的孩子的。
算法题是用来衡量你思考和解决问题的能力的。如果是大公司的研发岗位,面一些很难的算法题我也不觉得为过,当然,不代表一定要答出最完美的答案,更重要的是你的思考、沟通、验证、以及执行过程。我当初在面试百度的时候,面的是一个算是很高端的字符串匹配题,最完美的答案(改进版 AC 自动机)我当时是既不知道又是即使知道了也写不出来,然而我给出了我能力范围内最漂亮的答案(后缀数组),复杂度虽然多了一个 lgN,但面试官也看到了我的分析能力以及思考过程的清晰、方案的完整度以及快速可实施性,后来一样还是过了。至于“ACM 级别”,我想你太小瞧 ACM 了,真的,就这道题目,在 ACM 圈子里是最 low 的模板题而已,稍微集训过几个月的人都会,完全不值得讨论……
至于“没本事不要设立高门槛”,我倒是觉得,不管有没有本事,有钱就有资格设置高门槛。至于门槛是设在这种看似不直接产生作用的算法能力上,还是设在什么管理、项目经验上,还是设在外貌性别上,这是企业站在自己的角度根据自己的需求选择的,你觉得不合适,大可选择别的企业,而不是到处抱怨。大企业,以及大企业出身的管理人员,尤其是面试应届毕业生的时候,都有可能会更倾向于成长型的员工。这种情况下,不面算法面什么?面你行业背景吗?面你项目经历吗?
可笑死了,没本事就嘲笑别人没本事。
还有一些情况是这样子的,例如我问超大整数乘法然后对方说用 Python 直接用乘号,又或者说我问快速排序对方说用 Haskell 一行写完。这就如同一个面试者打开公文包掏出一个轮子说「我这正好有一个,不知道是否合适?」呃……你的百宝袋里面还有什么?
最后从面试官的角度来说,面试 ACM/ICPC 竞赛选手往往都很无聊。他们能够给出一个完美的轮子,但我不觉得我能从他们身上学到新东西。(面试过足够多的人后,要见到一个比已知完美轮子更完美的轮子其实非常难。)更有趣的面试者会说,「你知道吗,其实中国古代独轮手推车的轮子设计得比古罗马战车的轮子要合理」。其实我不知道你在说什么,但如果你能够把整套理论说得自圆其说的话我觉得你至少有点思维能力,同时你还真的对轮子感兴趣。事后我可能会去搜索一下看看你说的理论是否正确,但至少我会学到点新东西。
当然啦。。看 C++ 要看 leveldb, 看 C 要看 redis
我告诉你一个识别 C++ 代码质量的诀窍:找几个 class,如果其 dtor 有 delete 或释放资源的操作,看看作者是否同时正确禁用了 copy ctor 和 assignment operator(或者正确实现了它们,如果 class 确实应该是 copyable 的话),这反映了作者设计 C++ class 的基本功:正确管理内存和其他资源,以及他有没有认真读过 Effective C++。
其实,一个人要成牛人,最重要的不是看过多少书,而是有没有一个自己的世界观,并且从这个世界观出发,知道什么要做,什么能做,什么要坚持,什么要追求,什么是命中注定,什么是此生无缘,然后才能选 A 不选 B,有决断心和行动力。为此,得要体会过了别人选择的艰难,明白所要追求事业的难度,然后自己的选择才有意义。这些可以通过读书,也可以通过别的方式。
在这个行业当实习生,待遇恰恰是最不重要的,你的起点高度跟你几年后能达到的水准没有任何必然关系。而且,你到岗后的努力也比你一开始的选择更加重要。
- 灵魂机器 答过的问题 - 知乎
- fov
@ 
<---------<----------<----------<---------在像幅不变的情况下,如果增大焦距;就需要把 field of view 缩小;FOV 缩小,远处的东西就会变大.
\ |\ bigger | \ -__ <---------------- | \ | ---- _____ focal distance | \ | | ---- __. | |\ --+-------------+---------------X small fov, big f ---+---+-X big fov, small.
- fov
- 有多少程序员后悔英语没学好?或者庆幸学好了? - 知乎
@ 英语想要投入日常生活中使用还是比较难的,不过幸好有声称“我 6 级差点就到 600”的老婆,我实在听不懂就让她弄,啊哈哈哈。
我就是活生生没学好英语的受害者。去年面试 facebook onsite 之后被拒,问原因, recruiter 说你的技术很好,但是我们担心你在工作上用英语沟通会有问题,建议你去报个英语班过一两年再来应聘,尼玛
看,“英语不学好,老死在内地”这话没说错吧
- 有多少程序员后悔英语没学好?或者庆幸学好了? - 知乎
- Think different. - Original Ad
@ Here’s to the crazy ones.
The misfits.
The rebels.
The troublemakers.
The round pegs in the square holes.The ones who see things differently.
They’re not fond of rules.
And they have no respect for the status quo.You can quote them, disagree with them,
glorify or vilify them.
About the only thing you can’t do is ignore them.Because they change things.
They push the human race forward.
While some may see them as the crazy ones,
we see genius.Because the people who are crazy enough to think
they can change the world, are the ones who do.Steve Jobs narrated version.
- 最棒的征兵广告_土豆_高清视频在线观看
@ If you are, you breathe.
If you breath, you talk.
If you talk, you ask.
If you ask, you think.
If you think, you search.
If you search, you experience.
If you experience, you learn.
If you learn, you grow.
If you grow, you wish.
If you wish, you find, and if you find, you doubt.
If you doubt, you question.
If you question, you understand, and if you understand, you know.
If you know, you want to know more.
If you want to know more, you are alive.
- 最棒的征兵广告_土豆_高清视频在线观看
- Think different. - Original Ad
- What the fuck am I reading?
@ 调查结果如下:
- 绝大多数母语成年人士的词汇量为 20,000–35,000 words
- 8 岁的母语人士平均词汇量为 10,000 words
- 4 岁的母语人士平均词汇量为 5,000 words
- 母语人士的词汇量大小主要是 4 到 15 岁之间的阅读量决定
令人比较丧气的结果如下:
- 绝大多数外语人士的词汇量仅为 4,500 words
- 在英语国家居住的(?非)母语人士词汇量平均仅为 10,000 words
不论是国内还是国外的考试要求词汇量,真的是太低了,四六级只有五六千,专四专八也就才一万三,托福雅思考试被誉为外语水平最高等级测试,词汇量要求不过一万,老外压根没想过中国人外语能学的多好。
而词汇量一万,只不过是母语国家 8 岁小孩的词汇水平,将会在听说读写中遇到极大的障碍!

- What the fuck am I reading?
- Koans / Tips
@ 这种事情,就让他们一群傻逼去闹吧,看淡了就行。坚持自己的兴趣,获不获奖真的不重要。学到知识是自己的。傻逼终究还是傻逼。
我无意神化史蒂夫·乔布斯,但他老人家说的话实在是太到位了:
和聪明人在一起工作,最大的好处就是不用考虑他们的自尊。
成吉思汗
It is not enough to succeed; everyone else must fail.
但要避免“金锁”,不要在局部最高点沾沾自喜!Java 高手还要去学 Ruby、Perl。
Worst musician in the band。宁为狮尾,不为狐头。
A jazz musician friend of mine told me this:
If you are not the worst musician in in your band, you should immediately switch bands.
I work at Spotify. I feel like a piece of shit programmer almost every day. I didn’t at my last workplace. So I left and started at Spotify.
When the time comes when I no longer feel like a piece of shit programmer here, I’ll quit and move on to a place that can once again make me feel like piece of shit.
This strategy has worked out really well for me during my career.
“Good morning, Dave,” said HAL.
然后我截图了一个著名电影《2001 太空漫游》里对电脑 HAL 9000 的描述:这机器就跟人类一样,能表达情绪的。但我们也不知道它是被程序写好表现得这样,还是说它真的有感觉……
Well, he acts like he has genuine emotions. Hum, of course, he’s programmed that way to make it easier for us to talk to him. But as to whether or not he has feelings is something I don’t think anyone can truthfully answer.

posts
gone girl
But I made him smarter. Sharper.
I inspired him to rise to my level.
I forged the man of my dreams.
A meme (/ˈmiːm/ meem) is “an idea, behavior, or style that spreads from person to person within a culture.”
The gene has its cultural analog, too: the meme. In cultural evolution, a meme is a replicator and propagator—an idea, a fashion, a chain letter, or a conspiracy(共谋) theory. On a bad day, a meme is a virus.
(你不能说 meme 是流言蜚语,因为它是中性词。它更像是地方特色、风俗,roman’s way of living。有道上的翻译是“文化基因”,很好。)
注意不要和 mime 弄混,那是 mime(
maim),这是 meme(“两个我”)。 mime 引申出去一个词叫 mimic。MIME is an Internet standard, 互联网文本格式(比如
text/javascript)。intrusive thoughts
实际上有 intrusive
[ɪn'trusɪv]thoughts 的人有很多,包括丘吉尔首相自己也有。他无法忍受住在楼上,因为他总是有「忍不住要从阳台跳下去」的想法。Intrusive thoughts are unwelcome involuntary thoughts, images, or unpleasant ideas that may become obsessions, are upsetting or distressing, and can be difficult to manage or eliminate. When they are associated with obsessive-compulsive disorder (OCD), depression, body dysmorphic disorder (BDD), and sometimes attention-deficit hyperactivity disorder (ADHD), the thoughts may become paralyzing, anxiety-provoking, or persistent. Intrusive thoughts may also be associated with episodic memory, unwanted worries or memories from OCD, posttraumatic stress disorder, other anxiety disorders, eating disorders, or psychosis. Intrusive thoughts, urges, and images are of inappropriate things at inappropriate times, and they can be divided into three categories: “inappropriate aggressive thoughts, inappropriate sexual thoughts, or blasphemous religious thoughts”.
我也有个很 horrible 的 intrusive thoughts。
refs and see also
- http://www.zhihu.com/question/23848160#answer-5660473
- http://en.wikipedia.org/wiki/Intrusive_thoughts
Publish or Perish
It’s a thing I call “taste” (Linus Torvalds)
All Our Patent Are Belong To You | Tesla
When I started out with my first company, Zip2, I thought patents were a good thing and worked hard to obtain them. … After Zip2, when I realized that receiving a patent really just meant that you bought a lottery ticket to a lawsuit, I avoided them whenever possible.
The unfortunate reality is the opposite: electric car programs (or programs for any vehicle that doesn’t burn hydrocarbons) at the major manufacturers are small to non-existent, constituting an average of far less than 1% of their total vehicle sales.
Technology leadership is not defined by patents, which history has repeatedly shown to be small protection indeed against a determined competitor, but rather by the ability of a company to attract and motivate the world’s most talented engineers. We believe that applying the open source philosophy to our patents will strengthen rather than diminish Tesla’s position in this regard.
我必须承认,在现成的答案面前,再花时间设想解法确实有点“耽误功夫”,而且自己的解法往往不能跟现成答案对比,有时候甚至差很多。这当然让人难为情,但是持续的比较、思考所带来的收获,远比“拿现成的来用”的收获要大。
再看一下,其实 X/Y 表示的是线性空间 X 里面的向量投影到线性空间 Y 后相等(或者说 Congruent)。比如二维平面 x-y,用 (x,y)表示。(x,0)表示所有 y 为 0 的向量集合,显然也是一个线性空间。则 (x,y)/(x,0)这个 Quotient Space 里的(2, 2) 和(2, 8)一样(因为投影把 y 方向的信息忽略了)。
In linear algebra, the quotient of a vector space V by a subspace N is a vector space obtained by “collapsing” N to zero. The space obtained is called a quotient space and is denoted V/N (read V mod N or V by N).
一鼓作气,再而衰,三而竭
- Koans / Tips
- TCP 连接的建立和终止过程 - 辛未羊的博客
@ [SYN+SYN/ACK+ACK] +-------+ +-------+ | | --->--SYN------->---+ | | 客户端发送一个TCP的SYN=1,Seq=X的包到服务器端口 | | | | | | client| ---<--SYN/ACK---<---+ | server| 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包 | | | | | | | +-->------ACK--->---- | | 客户端发送ACK=Y+1, Seq=Z +-------+ +-------+ [FIN+ACK; FIN+ACK] +-------+ +-------+ | | --->--FIN------->---+ | | 主动方发送Fin=1, Ack=Z, Seq= X报文 | | | | | | client| ---<------ACK---<---+ | server| 被动方发送ACK=X+1, Seq=Z报文 | | | | | | +--<--FIN-------<---- | | 被动方发送Fin=1, ACK=X, Seq=Y报文 | | | | | | | +-->------ACK--->---- | | 主动方发送ACK=Y, Seq=X报文 +-------+ +-------+Richard Stevens 先生在 UNP2e (UNIX 网络编程 卷 1:套接字联网 API) 的前言中写道:
I have found when teaching network programming that about 80% of all network programming problems have nothing to do with network programming, per se. That is, the problems are not with the API functions such as accept and select, but the problems arise from a lack of understanding of the underlying network protocols. For example, I have found that once a student understands TCP’s three-way handshake and four-packet connection termination, many network programming problems are immediately understood.
下面是我的 remix。
TCP 的三路握手
肯定是客户端先表白。
- 客户端对服务器:我要和你发展关系。(#1,SYN)
- 服务器对客户端:你可以和我发展关系。(#2,SYN,ACK)
- 客户端对服务器:在一起~(#3,ACK)
于是三次握手后,他们在一起了(连接建立了)。
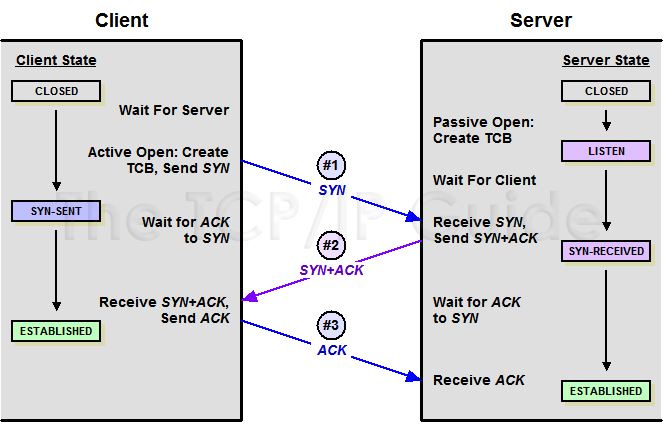
TCP 的四次挥手
可以是客户端说分手,也可以是客户端。这里以客户端作为负心汉。
- 客户端对服务器:恋爱谈完了,我们分手把。(#1,FIN)
- 服务器对客户端:可以的。(如果还有财务纠纷那就先还钱,不让分手的。)(#2,ACK)
- 服务器对客户端:那就分。(#3,FIN)
- 客户端对服务器:恩。(#4,ACK)
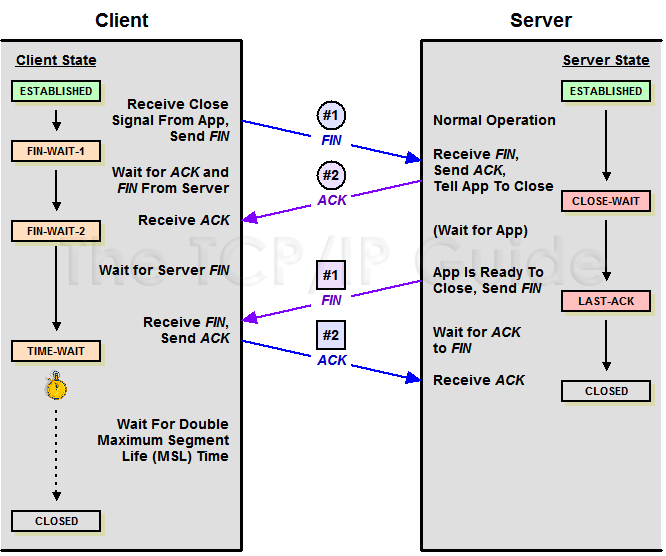
- 计算机网络 · GitBook
@ - HTTP
@ HTTP 的特性 - HTTP构建于TCP/IP协议之上,默认端口号是80 - HTTP是无连接无状态的
- 幂等的意味着对同一URL的多个请求应该返回同样的结果。
- 在 HTTP 1.1 版本中,默认情况下所有连接都被保持,如果加入 “Connection: close” 才关闭。目前大部分浏览器都使用 HTTP 1.1 协议,也就是说默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况。
- TCP
@ TCP 的特性
- TCP提供一种面向连接的、可靠的字节流服务
- 在一个TCP连接中,仅有两方进行彼此通信。广播和多播不能用于TCP
- TCP使用校验和,确认和重传机制来保证可靠传输
- TCP使用累积确认
- TCP使用滑动窗口机制来实现流量控制,通过动态改变窗口的大小进行拥塞控制
- Socket
@ - Socket 起源于 Unix ,Unix/Linux 基本哲学之一就是“一切皆文件”,都可以用“ 打开(open) –> 读写(write/read) –> 关闭(close)”模式来进行操作。因此 Socket也被处理为一种特殊的文件。
- 二叉树
@ 二叉树:二叉树是有限个结点的集合,这个集合或者是空集,或者是由一个根结点和两株互不相交的二叉树组成,其中一株叫根的做左子树,另一棵叫做根的右子树。
二叉树的性质:
- 性质1:在二叉树中第 i 层的结点数最多为2^(i-1)(i ≥ 1)
- 性质2:高度为k的二叉树其结点总数最多为2^k-1( k ≥ 1)
- 性质3:对任意的非空二叉树 T ,如果叶结点的个数为 n0,而其度为 2 的结点数为 n2,则:n0 = n2 + 1
满二叉树:深度为k且有2^k -1个结点的二叉树称为满二叉树
完全二叉树:深度为 k 的,有n个结点的二叉树,当且仅当其每个结点都与深度为 k 的满二叉树中编号从 1 至 n 的结点一一对应,称之为完全二叉树。(除最后一层外,每一层上的节点数均达到最大值;在最后一层上只缺少右边的若干结点)
性质4:具有 n 个结点的完全二叉树的深度为 log2n + 1
注意:仅有前序和后序遍历,不能确定一个二叉树,必须有中序遍历的结果
- 平衡二叉树
@ 平衡二叉树(balanced binary tree),又称 AVL 树。它或者是一棵空树,或者是具有如下性质的二叉树:
- 它的左子树和右子树都是平衡二叉树,
- 左子树和右子树的深度之差的绝对值不超过1。
平衡二叉树是对二叉搜索树(又称为二叉排序树)的一种改进。二叉搜索树有一个缺点就是,树的结构是无法预料的,随意性很大,它只与节点的值和插入的顺序有关系,往往得到的是一个不平衡的二叉树。在最坏的情况下,可能得到的是一个单支二叉树,其高度和节点数相同,相当于一个单链表,对其正常的时间复杂度有O(log(n))变成了O(n),从而丧失了二叉排序树的一些应该有的优点。
- B-树
@ B-树:B-树是一种非二叉的查找树, 除了要满足查找树的特性,还要满足以下结构特性:
一棵 m 阶的B-树:
- 树的根或者是一片叶子(一个节点的树),或者其儿子数在 2 和 m 之间。
- 除根外,所有的非叶子结点的孩子数在 m/2 和 m 之间。
- 所有的叶子结点都在相同的深度。
B-树的平均深度为logm/2(N)。执行查找的平均时间为O(logm);
- Trie 树
@ Trie 树,又称前缀树,字典树, 是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
Trie 树查询和插入时间复杂度都是 O(n),是一种以空间换时间的方法。当节点树较多的时候,Trie 树占用的内存会很大。
Trie 树常用于搜索提示。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。
- 哈希表
@ - 冲突解决
@ 链地址法
链地址法的基本思想是,为每个 Hash 值建立一个单链表,当发生冲突时,将记录插入到链表中。
开放地址法
http://open.163.com/movie/2010/12/1/S/M6UTT5U0I_M6V2U3R1S.html
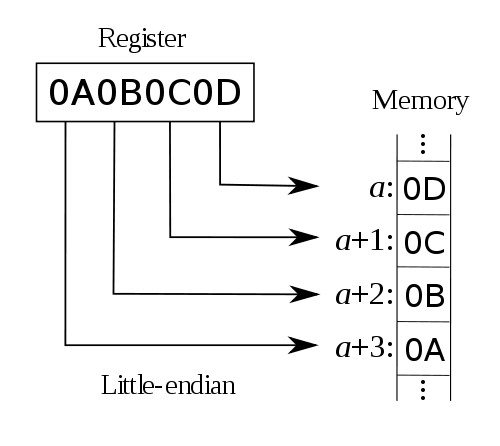
比如数字0x12345678在两种不同字节序CPU中的存储顺序如下所示:
Big Endian 低地址 高地址 ----------------------------------------------------> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | 12 | 34 | 56 | 78 | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Little Endian 低地址 高地址 ----------------------------------------------------> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | 78 | 56 | 34 | 12 | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+union test { short i; char str[sizeof(short)]; } tt; void main() { tt.i = 0x0102; if(sizeof(short) == 2) { if(tt.str == 1 && tt.str == 2) printf("大端字节序"); else if(tt.str = 2 && tt.str == 1) printf("小端字节序"); else printf("结果未知"); } else printf("sizof(short)=%d,不等于2",sizeof(short)); }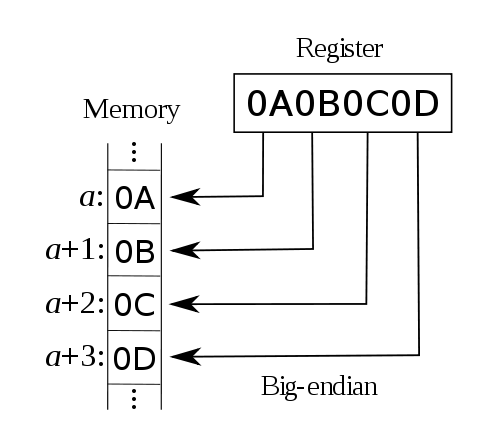
- 冲突解决
- HTTP
- qiu-deqing/FE-interview: 收集的前端面试题和答案
@ HTTP method
- 一台服务器要与HTTP1.1兼容,只要为资源实现GET和HEAD方法即可
- GET是最常用的方法,通常用于请求服务器发送某个资源。
- HEAD与GET类似,但服务器在响应中值返回首部,不返回实体的主体部分
- PUT让服务器用请求的主体部分来创建一个由所请求的URL命名的新文档,或者,如果那个URL已经存在的话,就用干这个主体替代它
- POST起初是用来向服务器输入数据的。实际上,通常会用它来支持HTML的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送到要去的地方。
- TRACE会在目的服务器端发起一个环回诊断,最后一站的服务器会弹回一个TRACE 响应并在响应主体中携带它收到的原始请求报文。TRACE方法主要用于诊断,用于验证请求是否如愿穿过了请求/响应链。
- OPTIONS方法请求web服务器告知其支持的各种功能。可以查询服务器支持哪些方法或者对某些特殊资源支持哪些方法。
- DELETE请求服务器删除请求URL指定的资源
- css sprite是什么,有什么优缺点
概念:将多个小图片拼接到一个图片中。通过background-position和元素尺寸调节需要显示的背景图案。
优点:
- 减少HTTP请求数,极大地提高页面加载速度
- 增加图片信息重复度,提高压缩比,减少图片大小
- 更换风格方便,只需在一张或几张图片上修改颜色或样式即可实现
缺点:
- 图片合并麻烦
- 维护麻烦,修改一个图片可能需要从新布局整个图片,样式
refs and see also
- paddingme/Front-end-Web-Development-Interview-Question: 前端开发面试题大收集
- 4ker/recipes: Some code snippets for sharing
- 4ker/annotated-git-1.0
- 为什么在 CPU 中要用 Cache 从内存中快速提取数据? - 知乎
@ 既然CPU速率高, 内存速率慢,那么中间加一个Cache的目的就是为了让存储体系可以跟上CPU的速度.
普通的CPU+DRAM内存的结构, 如果没有设计Cache, 每一次CPU都要找内存要数据, 这个延迟估计在80个时钟周期左右. 这是因为CPU要从内部运算核心将请求发到CPU边缘的总线上, 从总线上电路板, 到达北桥, 再上电路板到达DRAM. DRAM搜索到数据后如此再送回去. CPU动作那么快, 等的黄花菜都凉了.如果加了Cache会怎样? L1 Cache, 访问延迟在4个周期左右, L2 Cache, 延迟在15个周期左右, L3Cache, 延迟在50个周期左右. 但是由于添加了很多Cache, CPU访问内存的速度被降低了, 需要120个周期左右. 如果CPU需要的内容, 90%在L1 Cache里有, 6%在L2 Cache里有, 3%在L3 Cache里有, 1%要去找DRAM拿. 那么整个存储体系的等效延迟就是: 7.2个时钟周期.这不是爽歪了么??
预先读取,为什么cpu不能做呢?预取(prefetch)这件事cpu的确不做, 是Cache在做, 每一集的Cache都会有自己的 prefetcher. 而实际上L1 Cache已经被融合进CPU内部里了, L1I和L1D和CPU流水线简直就是紧挨在一起, L2 Cache又紧挨着CPU的L1D. 所以L1I, L1D, L2它们做预取, 和 CPU自己做是一回事! 而且CPU跑多快, 预取的速度就有多快! 上面凭什么说“CPU需要的内容, 90%在L1 Cache里有, 6%在L2 Cache里有”? 就是因为Cache中数据大多是复用的, 而且Cache基于历史数据还一直在预取! 而CPU和prefetcher像极了老总和小秘的关系, 比如:
- 在校学生一枚,面对高性能服务器开发、分布式系统、缓存系统等等。该如何最快最好的提升自己的技术水平呢? - 知乎
@ 作为学生的你,你现在学习的 算法、数据结构、网络原理、操作系统、组件原理、汇编语言 等等科目,是内功!内功需要按顺序,循序渐进地学习,而且学习过程非常痛苦且艰难!那些招式与内功相比,算个球!
- HTTP 协议入门 - 阮一峰的网络日志
@ HTTP 是基于 TCP/IP 协议的应用层协议。它不涉及数据包(packet)传输,主要规定了客户端和服务器之间的通信格式,默认使用80端口。
最早版本是1991年发布的0.9版。该版本极其简单,只有一个命令GET。
1996年5月,HTTP/1.0 版本发布,内容大大增加。
首先,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。这为互联网的大发展奠定了基础。
其次,除了GET命令,还引入了POST命令和HEAD命令,丰富了浏览器与服务器的互动手段。
再次,HTTP请求和回应的格式也变了。除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
其他的新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
- Content-Type 字段
关于字符的编码,1.0版规定,头信息必须是 ASCII 码,后面的数据可以是任何格式。因此,服务器回应的时候,必须告诉客户端,数据是什么格式,这就是 Content-Type字段的作用。
下面是一些常见的Content-Type字段的值。
text/plain audio/mp4 text/html video/mp4 text/css application/pdf image/jpeg application/zip image/png application/atom+xml image/svg+xml application/javascriptMIME type还可以在尾部使用分号,添加参数:
Content-Type: text/html; charset=utf-8HTTP/1.0 版的主要缺点是,每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
TCP连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)。所以,HTTP 1.0版本的性能比较差。随着网页加载的外部资源越来越多,这个问题就愈发突出了。
1997年1月,HTTP/1.1 版本发布,只比 1.0 版本晚了半年。它进一步完善了 HTTP 协议,一直用到了20年后的今天,直到现在还是最流行的版本。
1.1 版的最大变化,就是引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。
客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。不过,规范的做法是,客户端在最后一个请求时,发送Connection: close,明确要求服务器关闭TCP连接。
目前,对于同一个域名,大多数浏览器允许同时建立6个持久连接。
2009年,谷歌公开了自行研发的 SPDY 协议,主要解决 HTTP/1.1 效率不高的问题。
这个协议在Chrome浏览器上证明可行以后,就被当作 HTTP/2 的基础,主要特性都在 HTTP/2 之中得到继承。
HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析HTML源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
- 浅谈字节序(Byte Order)及其相关操作 - Jeffrey Zhao - 博客园
@ 对于我们常用的CPU架构,如Intel,AMD的CPU使用的都是小字节序,而例如Mac OS以前所使用的Power PC使用的便是大字节序(不过现在Mac OS也使用Intel的CPU了)。此外,除了大字节序和小字节序之外,还有一种很少见的中字节序(middle endian),它会以2143的方式来保存数据(相对于大字节序的1234及小字节序的4321)。
??? network???
Master-1.注重实效的哲学 | PaddingMe’s Blog
- 你的字典里有多少元素? - 老赵点滴 - 追求编程之美
@ “字典”或者说“哈希表”大家都会用,这真是一个好东西,只要创建了之后就可以不断的丢东西进去,添加删除都是O(1)操作,那叫一个快字了得。不过这里我要再次引用 Alan Perlis 的名言:
Lisp programmers know the value of everything but the cost of nothing.
目的是想提醒做事“不要忘记背后的代价”。
- 《写给大家看的设计书》读书笔记 | PaddingMe’s Blog
@ 约书亚树
一旦你能够说出什么东西的名字,就会很容易注意到它。你就会掌握它,拥有它,使它在你的控制中。
- TCP使用滑动窗口机制来实现流量控制,通过动态改变窗口的大小进行拥塞控制
TODO?
- Code point - Wikipedia, the free encyclopedia
refs and see also
boost bind 源码剖析 - coredump - SegmentFault
leveldb源码分析(1)--arena内存池的实现 - redteam - SegmentFault
STL区间成员函数及区间算法总结 - 大CC - SegmentFault
《Effective C++》 - mikey219 - SegmentFault
二叉排序树实现(C++封装) - zhoutk - SegmentFault
快速了解C/C++的左值和右值 - JK - SegmentFault
Identicon - Wikipedia, the free encyclopedia
Morse code - Wikipedia, the free encyclopedia
所以, 倾情推荐:
http://oj.leetcode.com LeetCode Online Judge
只要每道题都可以保证 3 遍以内过, 所有湾区工作 entry level 随便挑. 涉及到的基本都是 Linked List, DP, BST 这样的简单数据结构或者算法题.
你人还是不够聪明,这个问题一出来你就应该知道他背诵的版本是 hash 啦。。。你应该顺着他说 hash,这不是开玩笑。
Big O notation - Wikipedia, the free encyclopedia
Cayley’s formula - Wikipedia, the free encyclopedia
- 软件测试 - 话题精华 - 知乎
@ 软件测试就是利用测试工具按照测试方案和流程对产品进行功能和性能测试,甚至根据需要编写不同的测试工具,设计和维护测试系统,对测试方案可能出现的问题进行分析和评估。执行测试用例后,需要跟踪故障,以确保开发的产品适合需求。
- 冒烟测试_百度百科
@ 这一术语源自硬件行业。对一个硬件或硬件组件进行更改或修复后,直接给设备加电。如果没有冒烟,则该组件就通过了测试。在软件中,“冒烟测试”这一术语描述的是在将代码更改嵌入到产品的源树中之前对这些更改进行验证的过程。在检查了代码后,冒烟测试是确定和修复软件缺陷的最经济有效的方法。冒烟测试设计用于确认代码中的更改会按预期运行,且不会破坏整个版本的稳定性。
In computer programming and software testing, smoke testing (also confidence testing, sanity testing) is preliminary testing to reveal simple failures severe enough to (for example) reject a prospective software release. A smoke tester will select and run a subset of test cases that cover the most important functionality of a component or system, to ascertain if crucial functions of the software work correctly.:37 When used to determine if a computer program should be subjected to further, more fine-grained testing, a smoke test may be called an intake test.
sanity,
['sænəti],n. 明智;头脑清楚;精神健全;通情达理For example, a smoke test may address basic questions like “Does the program run?”, “Does it open a window?”, or “Does clicking the main button do anything?” The process of smoke testing aims to determine whether the application is so badly broken as to make further immediate testing unnecessary. As the book Lessons Learned in Software Testing puts it, “smoke tests broadly cover product features in a limited time … if key features don’t work or if key bugs haven’t yet been fixed, your team won’t waste further time installing or testing”.
Smoke tests frequently run quickly, often in the order of a few minutes, giving the benefit of quicker feedback and faster turnaround than the running of full test suites, which can take hours – or even days.
refs and see also
是的,我想说,他妈的没接触到技术性的东西你不会自己去接触啊,
都二十好几的人了,还在等人把东西嚼碎了喂你嘴里????????
目前国内 QA 的工作面很广。web 上点鼠标的是 QA,linux 上写脚本的是 QA,编写单元测试的是 QA,负责工具开发的是 QA,推广 TDD 或者敏捷的也是 QA。
根据 QA 的工作类型区分前途是比较合适的。
黑盒测试工程师
- 自动化测试工程师
@ 使用 qtp,selenium,watir,或者是其他的技术框架来自动化测试工作的。在 unix 上做自动化工作的,比如编写 shell 脚本,或者其他的脚本,也是属于此类。
因为自动化在回归阶段可以节省人力,可以有效的对产品的质量进行度量,并且可以不断的累积,结合覆盖率统计,或者需求覆盖统计等手段,可以很好的保证产品线的开发质量。所以自动化是很重要的技术。大公司一般都有这样的工作和人员配备。
不过前端的自动化,和后端的自动化,仍旧有一些弊病。很多公司倾向于使用分层自动化去解决不同层面的质量问题。这部分相对有点技术含量,大公司招人,也是必考的内容。相对来说,有点前途。但是一旦自动化方案稳定了,那么这类人也会面临职业发展困境。只不过目前自动化仍然在不断发展,这个问题暴露的不是很隐蔽。这个领域的工程师将来会两极分化,一部分转向自动化工具的研发,一部分转向自动化case的维护。
- 自动化测试工程师
- 白盒测试工程师
@ 这部分人主要做代码分析,审核,编写必要的单元测试,并关注代码的各种覆盖率情况。
- 白盒测试工程师
- 测试架构师
@ 负责规划辅助测试的各种工具和平台。基本上是全能的。并能对自动化,技术改进和测试理论有很好的贡献。属于大牛级别。比如研究封装开源的框架,或者开发新技术,来提高 QA 的测试效率和保证质量覆盖。 不过这个职位将来会比较尴尬,可能会并到测试工具开发工程师中,或者在对应的工具开发团队担任管理。这个职位,将来会死掉。企业不需要太多的 title。
- 测试架构师
- 性能测试工程师
@ 国内的黄金职业,技术相对专业,但是精通了基本可以一劳永逸。性能测试的理论基本跟开发技术关联不大,所以还是很稳当的。
- 性能测试工程师
- 安全测试工程师
@ 严格来说不算 QA,虽然 QA 里面有做这个的,但是专业理论要求较高,跟开发技术的关联性也不是太大,具备通用性,所以也是很黄金的。
- 安全测试工程师
- 测试管理
@ 去做 QA 的管理角色,比如带项目,QA 数据统计和分析。带团队等。自然也是很黄金的了。
- 测试管理
对于大部分公司来说,职位并不是严格的,很多人可能是一职多能。
发展方向主要有以下几种
- 走 QA 技术路线,测试分析,自动化,白盒,或者专心走性能测试,安全测试,测试规划等。
- 走 RD 技术路线,转行做研发。这个例子也很多。开发肯定比 QA 更可靠。 已经有不少先例了。
- 走管理路线。有管理爱好的,可以往这个方向发展。
- 走业务路线。去做产品经理,规划产品设计。也是蛮不错的职位。
- 开发测试工具,测试解决方案,提供测试服务。类似于 51testing 和博为峰这样的公司。
为什么微软叫 SDET 而不是 QA?Software Development Engineer in Test,SDET 中文叫:软件测试开发工程师。主体还是 SDE,做的还是软件开发,只不过偏测试方面的开发。这个不是专职的测试。Google、Amazon 中也有 SDET,但是大家都知道,真正能保证软件质量的还是开发团队自己。
你需要很清楚的明白一点,对于任何一个公司,如果“产出性”的人多于“支持性”的人,那么这个公司是往上走的,如果“支持性”的人多于“产出性”的人,那么这个公司一定处于下坡路上。所谓“产出性”还是“支持性”,就看你的团队或是你的部门是“财务中心 Finical Center”还是一个“成本中心 Cost Center”了。
1 个好的工程师顶 10-100 个烂的工程师,1 个烂的工程师,可以很容易地创造 2-10 个工作机会。
- 软件测试的魅力何在?您为什么选择测试一行而不做开发?
@ 你让一场本该在用户面前发生的灾难,提前在自己面前发生了
会让你有一种救世主的感觉
拯救了这个用户,也拯救了这个软件,避免了他被卸载的命运再进一步,你还改变了你的程序员兄弟被骂娘的命运
你改变了你的老板破产的命运
你改变了你的兄弟们失业的命运
这大约就是测试的魅力所在为什么选择?
有的人喜欢创造世界,他们做了程序员
有的人喜欢拯救世界,他们做了测试员
代码是为了什么,当然是为了重复运行。如何保持 unit test 代码的稳定?主要靠好的 API设计。API 切实正确切割了需求,那么在重构的时候 API 就基本不用变化, unit test 也不用重写。以后你重构的时候,只要你的 unit test 覆盖的够好,基本跑一遍就知道有没有改成傻逼。可以节省大量的时间。
所以那些专门写不需要维护的软件的人,讨厌测试,也是情有可原的。
- 冒烟测试_百度百科
Memory hierarchy - Wikipedia, the free encyclopedia
:
Typical memory hierarchy (access times and cache sizes are approximations
of typical values used as of 2013 for the purpose of discussion; actual
values and actual numbers of levels in the hierarchy vary):
- CPU registers (8-256 registers)
~ immediate access, with the speed of the inner most core of the processor
- L1 CPU caches (32 KiB to 512 KiB)
~ fast access, with the speed of the inner most memory bus owned exclusively by each core
- L2 CPU caches (128 KiB to 24 MiB)
~ slightly slower access, with the speed of the memory bus shared between twins of cores
- L3 CPU caches (2 MiB to 32 MiB)
~ even slower access, with the speed of the memory bus shared between
even more cores of the same processor
- Main physical memory (RAM) (256 MiB to 64 GiB)
~ slow access, the speed of which is limited by the spatial distances
and general hardware interfaces between the processor and the memory
modules on the motherboard
- Disk (virtual memory, file system) (1 GiB to 256 TiB)
~ very slow, due to the narrower (in bit width), physically much
longer data channel between the main board of the computer and the
disk devices, and due to the extraneous software protocol needed on
the top of the slow hardware interface
- Remote Memory (such as other computers or the Internet) (Practically unlimited)
~ speed varies from very slow to extremely slow- 写给准备参加秋招的学弟学妹们一定要来看哦 - 671coder 的专栏 - 博客频道 - CSDN.NET
操作系统很重要吧,这个就不用说了,需要看的内容非常简单。大家把何昊老师出的《程序员面试笔试宝典》这本书第八章到第十章全都看一遍就可以了,计算机网络 9.1、 9.3、9.4 是重点,操作系统部分 10.1 和 10.2 是重点,对于数据库,可能只需要记得简单的语句就行了,然后范式、一些锁、主键外键、索引看一看记住就可以,事物是非常重要的,必须掌握。
C++ 是个好东西,需要准备的东西比较多,推荐看一下《C++ Primer》和《effective c++》想依靠 c++ 为门槛拿到不错的 offer 的话,这两本书打死也要看。最好边看边做笔记,把重点画下来,或者写 blog,我在网上认识一个 sdust 大二的大牛 zxf,他整理的 blog 就非常棒,还被评为了 csdn 的专栏达人,链接在此。
- 2.5 年, 从 0 到阿里 - 翡青的博客 - 博客频道 - CSDN.NET
@ 我的准备工作大致分为五方面内容: C++, Linux, 数据结构与算法, 计算机网络 (TCP/IP) 和操作系统. 如果一个本科生能够把这五方面的基础打得比较坚实再加上稍稍一点儿运气, 拿下互联网的 offer 是不在话下的, 另外如果你实力够强的话, 那仅需的一点儿运气也是不需要的, 在此我引用 671 学长的一句关于面试的经典: ”面试 = 运气(50-n)/100 + 实力(50+n)/100, n=f(x),x 即实力,n 与 x 成正比关系, 这就意味着: 你实力越强, 对运气的依赖性越低, 所以实力才是非常重要的一个环节.”, 下面分别介绍一下我所准备的五方面内容。
- CS 基础 - 翡青的博客 - 博客频道 - CSDN.NET
- TCP/IP入门(1) –链路层
- …
一面问得问题有: (1)TCP 三次握手过程, 与为啥需要采用三次握手; (2)TCP TIME_WAIT 状态的原因; (3)C++ 虚函数机制 (C++ 对象模型); (4)C++ Static 关键字; (5)Select/Poll/Epoll 的异同 (使用与内部实现方面); (6)C++ 迭代器失效问题 (iterator 原理); (7)map/set 容器的实现原理 (红黑树知识 +STL 容器内部原理);
- 2.5 年, 从 0 到阿里 - 翡青的博客 - 博客频道 - CSDN.NET
线性代数的妙用:怎样在Windows画图软件中实现28度旋转? | Matrix67: The Aha Moments
- 想学好计算机算法,是否需要重新学数学呢? - 知乎
要学什么,就学什么。
要学算法,就学算法,遇到数学问题,就查,就问,不要分心。
要参加英文面试,就练习英文面试,别背单词,别练阅读,也不用管面试中说不到的话题。
要做什么,就准备什么。宁可简单粗暴,不要曲线救国。摊子铺大了,目标就模糊了,效率低,反馈慢,渐渐的就兜不回来了。
- C++ 求余用的“%”有与它效率相同的其它算法吗? - 知乎
@ Grisu 是把浮点数转换为字符串的算法。在 Chrome 里执行这段 JavaScript 实际上就调用了 Grisu:
document.write(1/3); // 0.3333333333333333在许多书籍也会谈及,当除数为常数时,可以把除法变成乘以除数的倒数。现在的编译器都会自动做这个优化。事实上,在上面的代码里,第二个除法(div /= 10)中的除数(10)就是常数,编译器会自动把它优化成64位乘法及右移指令,例如 clang 在 x86-64 目标下:
refs and see also
- Branch table - Wikipedia, the free encyclopedia
In computer programming, a branch table or jump table is a method of transferring program control (branching) to another part of a program (or a different program that may have been dynamically loaded) using a table of branch or jump instructions. It is a form of multiway branch. The branch table construction is commonly used when programming in assembly language but may also be generated by a compiler, especially when implementing an optimized switch statement where known, small ranges are involved with few gaps.
#include <stdio.h> #include <stdlib.h> typedef void (*Handler)(void); /* A pointer to a handler function */ /* The functions */ void func3 (void) { printf( "3\n" ); } void func2 (void) { printf( "2\n" ); } void func1 (void) { printf( "1\n" ); } void func0 (void) { printf( "0\n" ); } Handler jump_table[4] = {func0, func1, func2, func3}; int main (int argc, char **argv) { int value; /* Convert first argument to 0-3 integer (modulus) */ value = ((atoi(argv[1]) % 4) + 4) % 4; /* Call appropriate function (func0 thru func3) */ jump_table[value](); return 0; }- RapidJSON 代码剖析(一):混合任意类型的堆栈 - Milo的编程 - 知乎专栏
bool StartArray() { new (stack_.template Push<ValueType>()) ValueType(kArrayType); return true; }这里其实用了两个可能较少接触的 C++ 特性。第一个是 placement new,第二个是 template disambiguator。
ValueType* v = stack_.Push<ValueType>(); // (1)这里
Push<ValueType>是一个 dependent name,它依赖于 ValueType 的实际类型。这里编译器不能确认 < 为小于运算符,还是模板的 <。为了避免歧义,需要加入 template 关键字。这是 C++ 标准的规定,缺少这个 template 关键字 gcc 和 clang 都会报错,而 vc 则会通过(C++ 标准也容许实现这样的编译器)。和这个语法相近的还有 typename disambiguator。class Stack { Stack(Allocator* allocator, size_t stackCapacity); ~Stack(); void Clear(); void ShrinkToFit(); template<typename T> T* Push(size_t count = 1); template<typename T> T* Pop(size_t count); template<typename T> T* Top(); template<typename T> T* Bottom(); Allocator& GetAllocator(); bool Empty() const; size_t GetSize(); size_t GetCapacity(); };Stack s; *s.Push<int>() = 1; *s.Push<int>() = 2; *s.Push<int>() = 3; *s.Push<int>() = 4; for (int i = 0; i < 2; i++) { int* a = s.Pop<int>(2); std::cout << a[0] << " " << a[1] << std::endl; } // 输出: // 3 4 // 1 2
<
pocoproject/poco: POCO C++ Libraries - Cross-platform C++ libraries with a network/internet focus.
- 统计 n! 中 0 的个数 - jxlincong 的专栏 - 博客频道 - CSDN.NET
1024 的阶乘末尾有多少个 0,这个问题只要理清思想就很好解了。
有多少个 0 取决于有多少个 10 相乘,即 1024 拆成小单元后有多少个 10。由于 10 不是素数,所以直接用 10 进行计算的话会有很多问题,于是将 10 分解。
10 可以分解成 2x5,2 和 5 都是素数,由于每 2 个相邻的数中一定包含 2,所以只要计算出有多少个 5 就可以了(2 会在 5 之后及时出现)。
于是解法如下:
- 是 5 的倍数的数有:1024 /5 = 204 个(说明 1024! 的展开式中的数,因式分解的因子中,至少有 1 个含有 5 的个数)
- 是 25 的倍数的数有:1024/ 25 = 40 个(1024! 的展开式中的数,因式分解的因子中,至少有 2 个含有 5 的个数)
- 是 125 的倍数的数有:1024/ 125 = 8 个(1024! 的展开式中的数,因式分解的因子中,至少有 3 个含有 5 的个数)
- 是 625 的倍数的数有:1024/ 625 = 1 个(1024! 的展开式中的数,因式分解的因子中,至少有 4 个含有 5 的个数)
所以 1024! 中总共有 204+40+8+1=253 个因子 5。即 1024!后有 253 个 0
算题思想:
- (1)先找出有 1 个 5 的数
- (2)然后找出有两个 5 的,2 个 5 的数虽然在第一步算过了,但是两个中剩下的那个 5 还可以形成 0
- (3)之后就是找出有 3 个 5 的,4 个 5 的,直到 n 个 5(5 的 n 次方小于阶乘的数)
- 心智工具箱(4):执行意图 - 阳志平的网志
@ - (●—●) | 技术面之项目面试技巧大揭秘_牛客网
@ 为什么项目经历差不多,大家的面试分数差别很多?面试官问项目时都在考察什么?在项目经验弱的情况下,应届生应该如何回答面试官的问题,更能引导面试节奏,让面试官更有参与感?
做项目
- 语言/框架
- 工具
- 协议/模式
- 产品/职位
在上面填上自己的内容!
几个可以在叙述中强调的点:
- 难度
- 造轮子
- 兴趣
- 创新
有没有人带?
如何找资料?
如何管理进度?
如何协调其他成员?
核心难点和结果?
扩展和深入?
面试官的关注点:
- 能力
- 你了解哪些部分
- 你深入了解哪些
- 你横向了解哪些
- 潜力
- 你怎么解决问题
- 你如何举一反三
- 你怎么优化项目
- 你如何快速学习
你的博客?如何搭建的?
注意,不要夸夸其谈。要真诚、有理有据。
- 冒泡 答过的问题 - 知乎
@ 第二个是二分查找算法的面试,由于面试很容易出这个题,这题很大难点又是在于二分到最后的边界判断,所以给人出了这么个主意:
while start < end: if end - start < 5: #顺序搜索 else: mid = (start + end) / 2 #二分,略恩,就是问题规模小于一定量就改顺序查找,也是 O(lgN),而且保证不会写错,如果面试官问还可以跟他扯,说 5 个元素顺序 search 的话 cache 友好之类的,说不定就忽悠成功啦
如何区别 fly 这个词是指飞行还是苍蝇?脱离具体场景并无意义,所以得看你这 32 个 1 是做有符号数补码还是无符号数补码解释
具体到题主这个问题,这样理解比较好,先不考虑具体存储限制:
补码,-1 是……111111111111111111111111111111111(32 个 1 前导无限个 1)
而 4294967295 是……011111111111111111111111111111111(32 个 1 前导无限个 0)
但是,计算机中存数字,只能存有限位数,所以有符号 32 位整数用最前面的位表示前导是无限个 1 还是无限个 0,表示范围是 -231~231-1
而无符号数默认是前导无限个 0,所以 32 位无符号整数表示范围是 0~2^32-1- 为什么同样是解决一个问题,别人就能想出算法,而我却绞尽脑汁,百般尝试也不得其法? - 知乎
@ 能上大学,大家智商之间都没有多大差距,关键字在于态度。他们问我的这些问题我都碰到过,所以我可以一秒指出问题。练习越多,经验越丰富。层次越高,看问题越明白。这都是大量的代码和阅读堆出来的。
为什么同样是解决一个问题,别人就能想出算法,而我却绞尽脑汁,百般尝试也不得其法?
为啥我就能三分钟解决而你要三十分钟?
无他,唯手熟尔。
记得早年学习 window 编程时,都推荐 windows 核心编程,于是买了本研究,发现好难,很难读的下去。后来读完了 windows 程序设计上下册,回过头来再看,发现又好简单。
这种情况多半是你的知识体系不完善,本身学识和经验就跟别人差好多。表现出来好像是别人比你聪明,但很多时候并不是这样。
知识量不够,想法自然受到局限。经验不够难免要采坑。一步一步提升自己才是正经事儿。
- (●—●) | 牛客网
@ - (●—●) | 用不带头结点的单链表存储队列,其队头指针指向队头结点,队尾指针指向队尾结点,则在进行出队操作时()_牛客网
@ 当队列中只有一个元素时,出队后需要清空对头和队尾指针。
- (●—●) | 用不带头结点的单链表存储队列,其队头指针指向队头结点,队尾指针指向队尾结点,则在进行出队操作时()_牛客网
- (●—●) | 以下与数据的存储结构无关的术语是()_牛客网
@ 栈可以是顺序存储,也可以是链式存储,与存储结构无关。循环队列是队列的顺序存储结构,链表是线性表的链式存储结构,用散列法存储的线性表叫散列表,都与存储结构有关
存储结构是数据的逻辑结构用计算机语言的实现,常见的存储结构有: 顺序存储,链式存储 , 索引存储 ,以及 散列存储 。其中散列所形成的存储结构叫 散列表(又叫哈希表) ,因此哈希表也是一种存储结构。栈只是一种抽象数据类型,是一种逻辑结构,栈逻辑结构对应的顺序存储结构为顺序栈,对应的链式存储结构为链栈,循环队列是顺序存储结构,链表是线性表的链式存储结构
- (●—●) | 以下与数据的存储结构无关的术语是()_牛客网
- (●—●) | integer-to-roman_leetcode笔试题_牛客网
@ class Solution { public: string intToRoman(int num) { static const char *x[] = { "I", "II", "III", "IV", "V", "VI", "VII", "VIII", "IX" }; static const char *x0[] = { "X", "XX", "XXX", "XL", "L", "LX", "LXX", "LXXX", "XC" }; static const char *x00[] = { "C", "CC", "CCC", "CD", "D", "DC", "DCC", "DCCC", "CM" }; static const char *x000[] = { "M", "MM", "MMM" }; if( num >= 1000 ) { return string(x000[num/1000-1]) + intToRoman(num%1000); } else if( num >= 100 ) { return string(x00[num/100-1]) + intToRoman(num%100); } else if( num >= 10 ) { return string(x0[num/10-1]) + intToRoman(num%10); } else if( num >= 1 ) { return string(x[num-1]); } return string(); // num == 0 } };string result; while( num != 0 ) { if( num >= 1000 ) { result += string(x000[num/1000-1]); num %= 1000; } else if( num >= 100 ) { result += string(x00[num/100-1]); num %= 100; } else if( num >= 10 ) { result += string(x0[num/10-1]); num %= 10; } else if( num >= 1 ) { result += string(x[num-1]); break; } } return result;
- (●—●) | integer-to-roman_leetcode笔试题_牛客网
- (●—●) | minimum-depth-of-binary-tree_牛客网
@ class Solution { public: int run(TreeNode *root) { return minDepth( root, false ); } private: int minDepth( TreeNode *root, bool hasbrother ) { if( !root ) { return hasbrother ? INT_MAX : 0; } return 1 + min( minDepth( root->left, root->right ), minDepth( root->right, root->left ) ); } };
- (●—●) | minimum-depth-of-binary-tree_牛客网
- (●—●) | (●—●) | 类A是类B的友元,类C是类A的公有派生类,忽略特殊情况则下列说法正确的是()_牛客网
@ 类 A 是类 B 的友元, 类 C 是类 A 的公有派生类, 忽略特殊情况则下列说法正确的是 ()
- 类 B 是类 A 的友元
- 类 C 不是类 B 的友元
- 类 C 是类 B 的友元
- 类 B 不是类 A 的友元
BD
友元关系是单向的,不是对称,不能传递。
关于传递性,有人比喻:父亲的朋友不一定是儿子的朋友。
那关于对称性,是不是:他把她当朋友,她却不把他当朋友?✧(≖ ◡ ≖✿)
- (●—●) | (●—●) | 类A是类B的友元,类C是类A的公有派生类,忽略特殊情况则下列说法正确的是()_牛客网
- (●—●) | 顺时针打印矩阵_牛客网
@ #include <iostream> #include <algorithm> #include <iterator> #include <vector> using namespace std; class Solution { public: vector<int> printMatrix(vector<vector<int> > &matrix) { int row = matrix.size(), col = matrix[0].size(); int lr = col, ud = row-1; vector<int> ret( row*col ); int i = 0, j = -1, k = 0; while( k < row*col ) { if( lr > 0 && k < row*col ) { for( int m = 0; m < lr; ++m ) { ret[k++] = matrix[i][++j]; } --lr; } // right if( ud > 0 && k < row*col ) { for( int m = 0; m < ud; ++m ) { ret[k++] = matrix[++i][j]; } --ud; } // down if( lr > 0 && k < row*col ) { for( int m = 0; m < lr; ++m ) { ret[k++] = matrix[i][--j]; } --lr; } // left if( ud > 0 && k < row*col ) { for( int m = 0; m < ud; ++m ) { ret[k++] = matrix[--i][j]; } --ud; } // up } return ret; } }; int main() { vector<vector<int> > matrix = { {1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}, {13, 14, 15, 16} }; Solution sol; vector<int> ret = sol.printMatrix( matrix ); copy( ret.begin(), ret.end(), ostream_iterator<int>(cout, " ")); puts(""); }
- (●—●) | 顺时针打印矩阵_牛客网
- Learn X in Y Minutes
@ nice.
@include <-include/learnxinyminutes.md=
- Words
@ - Augusta Ada Byron
- Alonzo Church: 由人类或任何机器执行操纵符号的任何算法过程,都是可以由某个 TM 执行;
SEEEEEEEEmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm |- 8 -||------------- 32 -------------|- regularity, 一致性
- subordinant class / superclass
class hierarchy
System.out .err .exit

Control + R,
=,pow(2,31)↩The SI prefixes (metric prefix) are standardized for use in the International System of Units (SI) by the International Bureau of Weights and Measures (BIPM) in resolutions dating from 1960 to 1991.↩
IEC 80000-13:2008 is an international standard that defines quantities and units used in information science, and specifies names and symbols for these quantities and units. The standard is published by the International Electrotechnical Commission (IEC) and is part of the group of standards called ISO/IEC 80000, published jointly by the IEC and the International Organization for Standardization (ISO).↩