历史笔记 2
原载于 https://github.com/district10/blog/blob/master/_pages/notes.md。
- How many Computer Languages are there?
@ late 1940s first electronic computers & LLLs 1950s first HLLs for computers 1969 about 120 HLLs, about 15 in widespread use 1977 about 80 HLLs in active (non-trivial) use Today more than 2000 HLLs- Scripting Paradigm
So far, we have been thinking about languages suitable for solving very large problems, where the resulting programs are tens of thousands or more lines long, written and maintained by more than one person. However, not all problems require industrial-strength solutions, and different requirements have given rise to different kinds of languages. The situations where they are applicable are:
building applications by gluing together existing components controlling applications that have a programmable interface writing programs where ease of development is more important than anything else (such as run-time efficiency, or maintainability)
- Google Search
@ inurl:text intitle:text allintitle:text filetype:pdf site:pan.baidu.com weather:wuhan see more and...计算机相关词汇@- CGI(公共网关接口,Common Gateway Interface) — 在 Web 服务器上,用来在脚本和/或应用程序之间传输数据,然后将该数据返回给 Web 页面或浏览器。CGI 脚本经常是使用 Perl 语言创建的,它能够生成动态 Web 内容(包括电子商业购物篮、讨论组、调查表单以及实时新闻等)。
- CHS(柱面/磁头/扇区,Cylinder/Head/Sector) — FDISK 在分区期间所需的磁盘信息。
- CLU(命令行实用程序,Command Line Utility) — 从命令行会话或 shell 运行的程序,如 Tar 或 Mkdir。
- LILO(Linux 装载程序,LInux LOader) — 一种流行的分区引导管理器实用程序,能够引导到 Linux 以外的操作系统。它并不特定于文件系统。
- MIME(多用途因特网邮件交换,Multipurpose Internet Mail Exchange) — 允许文本电子邮件消息包含非文本(例如图形、视频或音频)数据的通信协议。
- PAM(可插入的认证模块,Pluggable Authentication Modules) — 用于系统安全性的可替换的用户认证模块,它允许在不知道将使用何种认证方案的情况下进行编程。这允许将来用其它模块来替换某个模块,却无需重写软件。
- RCS(修订控制系统,Revision Control System) — 一组程序,它们控制组环境下文件的共享访问并跟踪文本文件的变化。常用于维护源代码模块的编码工作。
- RFS(远程文件共享,Remote File Sharing) — 一个程序,它让用户访问其它计算机上的文件,就好象文件在用户的系统上一样。
- RPM(RPM 软件包管理器,RPM Package Manager) — 一种用于因特网下载包的打包及安装工具,它包含在某些 Linux 分发版中。它生成具有 .RPM 扩展名的文件。与 Dpkg 类似。
ag --pager less <qry> [<filename>]pt --color --group <qry> | less- 假脱机(Spool)(外围设备联机并发操作,Simultaneous Peripheral Operation On-Line) — 将数据发送给一个程序,该程序将该数据信息放入队列以备将来使用(例如,打印假脱机程序)。
- 隐写术(Steganography,
[,stegə'nɔgrəfi]n. 速记式加密)— 将一段信息隐藏在另一段信息中的做法。一个示例是在数字化照片中放置不可见的数字水印。 - Tux— 虚构的 Linux 企鹅吉祥物的名字。
- 工作目录(Working Directory)— 当前目录或用户当前工作时所在的目录的另一名称。
"kyyvs."Kyy"kp==="Kp:reg
- Vim notes
@ Yank the text you want to copy with
y[motion]- this text is saved in"and0registers. Delete the text you want to replace withd[motion]- this text is saved in"register. Paste the yanked text with"0pWe can now just type
@mto run this macro on the current line. Furthermore, we can type100@mto do this 100 times! Lifes looking pretty good.:%normal @aapply to this region.J合并行,并两行之间增加一个空格gJ合并行没有空格vip我一直使用 v i p 按键组合,快速选中一段,在代码块间使用非常方便。<c-a> <c-x>number++, number–cat /etc/fstabmount /cdromeject /cdromcd+ TABmd path/to/dir===mkdir -p path/to/dirrd path/to/dir===rmdir path/to/dird===dirs -V: lists last used directories- Bash:
set -o vi,set -o emacs - Zsh:
bindkey -v,bindkey -e C-t交换光标所在字符与其前的字符M-t交换光标所在的单词与前面单词的位置C-m相当于“回车键”
%s/重车,运营/运营,重车/g %s/,超速报警//g %s/,登录//g g/,设备工作正常/d g!/ACC/d- “Unix 用起来容易,但学习起来难”。
@ Unix/Linux 操作系统的使用作为实践性非常强的一门“技术”,有章可循。每一个命令的命令格式、参数、选项都可以通过阅读手册获得,所以用起来很容易。
但它学习起来,并不是每天扫地的阿姨一眼就能轻松掌握的工具。如作者所言,“设计 Unix 的目的不是为了学习而是为了使用。”为了达到使用 Unix 这一工具的目的,我们需要了解其“然”,也就是基本操作:了解如何登陆 Unix、如何使用 Unix 编辑文件、操作目录……
其实就是说,Unix 就要用。不要“学”太深,因为设计者的设计并不完美(不可能)。
- Helpful aliases for common git tasks
@ g→gitgst→git statusgl→git pullgup→git pull --rebasegp→git pushgd→git diffgdc→git diff --cachedgdv→git diff -w "$@" | view -gc→git commit -vgcR→git commit -v --amendgca→git commit -v -agcaR→git commit -v -a --amendgcmsg→git commit -mgco→git checkoutgcm→git checkout mastergr→git remotegrv→git remote -vgrmv→git remote renamegrrm→git remote removegsetr→git remote set-urlgrup→git remote updategrbi→git rebase -igrbc→git rebase --continuegrba→git rebase --abortgb→git branchgba→git branch -agcount→git shortlog -sngcl→git config --listgcp→git cherry-pickglg→git log --stat --max-count=10glgg→git log --graph --max-count=10glgga→git log --graph --decorate --allglo→git log --oneline --decorate --colorglog→git log --oneline --decorate --color --graphgss→git status -sga→git addgm→git mergegrh→git reset HEADgrhh→git reset HEAD --hardgclean→git reset --hard && git clean -dfxgwc→git whatchanged -p --abbrev-commit --pretty=mediumgsts→git stash show --textgsta→git stashgstp→git stash popgstd→git stash dropggpull→git pull origin $(current_branch)ggpur→git pull --rebase origin $(current_branch)ggpush→git push origin $(current_branch)ggpnp→git pull origin $(current_branch) && git push origin $(current_branch)glp→git log prettily
- Python notes
@ - 表面上看,tuple 的元素确实变了,但其实变的不是 tuple 的元素,而是 list 的元素。
- list 和 tuple 是 Python 内置的有序集合,一个可变,一个不可变。根据需要来选择使用它们。
if <条件判断1>: <执行1> elif <条件判断2>: <执行2> elif <条件判断3>: <执行3> else: <执行4>birth = int(raw_input(birth: ))要避免 key 不存在的错误,有两种办法,一是通过
in判断key是否存在:>>> Thomas in d >>> False所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
要保证 hash 的正确性,作为 key 的对象就不能变。在 Python 中,字符串、整数等都是不可变的,因此,可以放心地作为 key。而 list 是可变的,就不能作为 key
int(),float(),str(),bool()
原来返回值是一个 tuple!但是,在语法上,返回一个 tuple 可以省略括号,而多个变量可以同时接收一个 tuple,按位置赋给对应的值,所以,Python 的函数返回多值其实就是返回一个 tuple,但写起来更方便。
def power(x, n=2): s = 1 while n > 0: n = n - 1 s = s * x return s默认参数必须指向不变对象!
def add_end(L=None):为什么要设计
str、None这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。我们在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。- list:
[1, 2, 3] - tuple:
(1, 2, 3)
定义可变参数和定义 list 或 tuple 参数相比,仅仅在参数前面加了一个
*号。在函数内部,参数 numbers 接收到的是一个 tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括 0 个参数def calc(*numbers): sum = 0 for n in numbers: sum = sum + n * n return sum nums = [1, 2, 3] calc(*nums) 14>>> kw = {city: Beijing, job: Engineer} >>> person(Jack, 24, **kw) name: Jack age: 24 other: {city: Beijing, job: Engineer}- 参数定义的顺序必须是:必选参数、默认参数、可变参数和关键字参数。
- args 是可变参数,args 接收的是一个 tuple;
**kw是关键字参数,kw 接收的是一个 dict。
尾递归是指,在函数返回的时候,调用自身本身,并且,return 语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
>>> L[1:3] [Sarah, Tracy] for key in d: for value in d.itervalues(): for k, v in d.iteritems(): [x*x for x in range(1, 11)] isinstance(x, str) g = (x * x for x in range(10)) g.next()- map, reduce
filter(function, list)
def not_empty(s): return s and s.strip() filter(not_empty, [A, , B, None, C, ]) # 结果: [A, B, C]sorted([list], <function>)- 高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
In : def lazy_sum(*args): ...: def sum(): ...: ax = 0 ...: for n in args: ...: ax = ax + n ...: return ax ...: return sum ...: In : f = lazy_sum( 1, 2, 3, 4) In : f Out: <function __main__.sum> In : f() Out: 10在这个例子中,我们在函数 lazy_sum 中又定义了函数 sum,并且,内部函数 sum 可以引用外部函数 lazy_sum 的参数和局部变量,当 lazy_sum 返回函数 sum 时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
lambda x: x*ximport functools int2 = functools.partial(int, base=2) int2('1000000')注意到上面的新的 int2 函数,仅仅是把 base 参数重新设定默认值为 2,但也可以在函数调用时传入其他值:
int2("1000000", base=10)请注意,每一个包目录下面都会有一个
__init__.py的文件,这个文件是必须存在的,否则,Python 就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有 Python 代码,因为__init__.py本身就是一个模块,而它的模块名就是 mycompanyif __name__ == '__main__': test()
try: import json # python >= 2.6 except ImportError: import simplejson as json # python <= 2.5类似
__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的__author__,__name__就是特殊变量,hello 模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名;类似
_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;外部不需要引用的函数全部定义成 private,只有外部需要引用的函数才定义为 public。
from __future__ import division, use python3.x in python2.xclass Student(object): def __init__(self, name, score): self.name = name self.score = score In : class Me(object): ....: def __init__(this): ....: this.name = "shit" this.__private_var, this.__not_private_var__, this._not_private_but_dont_touch_me_please class Dog(Animal): pass instanceof (dog, Dog) instanceof (dog, Animal) # true def run_twice(animal): animal.run() animal.run()对于一个变量,我们只需要知道它是 Animal 类型,无需确切地知道它的子类型,就可以放心地调用
run()方法,而具体调用的run()方法是作用在 Animal、Dog、Cat 还是 Tortoise 对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种 Animal 的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:- 对扩展开放:允许新增 Animal 子类;
- 对修改封闭:不需要修改依赖 Animal 类型的
run_twice()等函数。
type(123), type("string") >>> import types __slots__ = (name, gender) class Student(object): def get_score(self): return self._score def set_score(self, value): if not isinstance(value, int): raise ValueError('score must be an integer!') if value < 0 or value > 100: raise ValueError('score must between 0 ~ 100!') self._score = value >>> s.score = 60 # OK,实际转化为s.set_score(60)@score.setter@property的实现比较复杂,我们先考察如何使用。把一个 getter 方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个 setter 方法变成属性赋值,于是,我们就拥有一个可控的属性操作
class Student(object): @property def birth(self): return self._birth @birth.setter def birth(self, value): self._birth = value @property def age(self): return 2014 - self._birth由于 Python 允许使用多重继承,因此,Mixin 就是一种常见的设计。只允许单一继承的语言(如 Java)不能使用 Mixin 的设计。
- Mixin
__str__(),print(Student("Michael"))__repr__ = __str____iter____getitem__,s = Student(),s__getattr__
当调用不存在的属性时,比如 score,Python 解释器会试图调用
__getattr__(self, score)来尝试获得属性__call__,s = Student(),s()import types type(u'abc')==types.UnicodeType isinstance(a, (str, unicode)) # string or unicode如果要获得一个对象的所有属性和方法,可以使用
dir()函数,它返回一个包含字符串的 list,比如,获得一个 str 对象的所有属性和方法:dir(Dog)getattr(),setattr(),hasattr()hasattr(Dog, "__init__")callable(Student())# true__getattr__
type()函数可以查看一个类型或变量的类型,Hello 是一个 class,它的类型就是 type,而 h 是一个实例,它的类型就是class Hello。type()to create class,__metaclass__ = <Class>try... except ...finally.
第二个 except 永远也捕获不到 ValueError,因为 ValueError 是 StandardError 的子类,如果有,也被第一个 except 给捕获了。
也就是说,不需要在每个可能出错的地方去捕获错误,只要在合适的层次去捕获错误就可以了。这样一来,就大大减少了写
try...except...finally的麻烦。import logging # log error and run, with error虽然用 IDE 调试起来比较方便,但是最后你会发现,logging 才是终极武器。
如果你听说过“测试驱动开发”(TDD:Test-Driven Development),单元测试就不陌生。
d = dict(a=1,b=2) d = dict({"a":1,"b":2}) raise FooError("invalid value: %s" % s) assert n != 0, "n is zero" logging, logging.info("n =%d" %n) import logging logging.basicConfig(level=logging.INFO) python -m pdb err.py pdb.set_trace() import pdb file-like object, `StringIO` <mode>=rb, f.read().decode("gbk") import codecs import os os.name os.path.abspath(".") os.getenv("PATH") os.path.split("url....") # dirname, basename import shutil split extension: os.path.splitext(str)==".py"我们把变量从内存中变成可存储或传输的过程称之为序列化,在 Python 中叫 pickling,在其他语言中也被称之为 serialization,marshalling(集结待发的), flattening 等等,都是一个意思。
try: import cPickle as pickle except ImportError: import pickle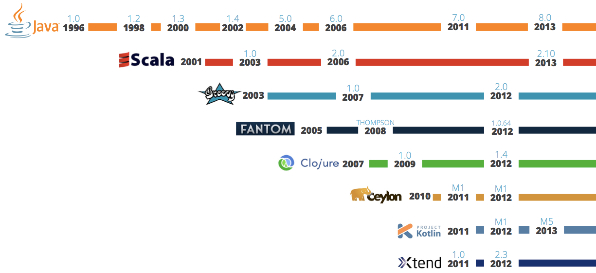
python 语言特定的序列化模块是 pickle,但如果要把序列化搞得更通用、更符合 Web 标准,就可以使用 json 模块。
json 模块的
dumps()和loads()函数是定义得非常好的接口的典范。当我们使用时,只需要传入一个必须的参数。但是,当默认的序列化或反序列机制不满足我们的要求时,我们又可以传入更多的参数来定制序列化或反序列化的规则,既做到了接口简单易用,又做到了充分的扩展性和灵活性。如果要启动大量的子进程,可以用进程池(pool)的方式批量创建子进程在 Unix/Linux 下,可以使用 fork() 调用实现多进程。要实现跨平台的多进程,可以使用 multiprocessing 模块。
进程间通信是通过 Queue、Pipes 等实现的。当多个线程同时执行
lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try…finally来确保锁一定会被释放。
import threading# 创建全局 ThreadLocal 对象: local_school = threading.local() import re s = r'ABC\-001' # Python的字符串 In : if re.match(r'^/d{3}\-\d{3,8}$', '010-12345'): ....: print 'ok' ....: In : >>> re.split(r'\s+', 'a b c') ['a', 'b', 'c'] >>> re.split(r'[\s\,]+', 'a,b, c d') ['a', 'b', 'c', 'd'] >>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345') >>> m <_sre.SRE_Match object at 0x1026fb3e8> >>> m.group(0) '010-12345' >>> m.group(1) '010' >>> m.group(2) '12345'- 贪婪匹配
>>> re.match(r'^(\d+)(0*)$', '102300').groups() ('102300', '')- 非贪婪匹配
>>> re.match(r'^(\d+?)(0*)$', '102300').groups() ('1023', '00') # 编译: >>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$') # 使用: >>> re_telephone.match('010-12345').groups() # ('010', '12345')
Python 之所以自称“batteries included”,就是因为内置了许多非常有用的模块,无需额外安装和配置,即可直接使用。
- modules
from collections import namedtuple from collections import deque q = deque(["a", "b", "c"]) q.append("x") q.appendleft("y") q append(), pop(), appendleft(), popleft() from collections import defaultdict from collections import OrderdDict from collections import counter %Base64 >>> n = 10240099 >>> b1 = chr((n & 0xff000000) >> 24) >>> b2 = chr((n & 0xff0000) >> 16) >>> b3 = chr((n & 0xff00) >> 8) >>> b4 = chr(n & 0xff) >>> s = b1 + b2 + b3 + b4 >>> s '�?@c'
import struct struct.pack('>I', 234523452345) import hashlib md5 = haslib.md5() md5.update(how to use md5 in python hashlib?) print md5.hexdigest()要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
import itertools natuals = itertools.count(1) for n in natuals: print n >>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种 >>> ns = itertools.repeat('A', 10) >>> natuals = itertools.count(1) >>> ns = itertools.takewhile(lambda x: x <= 10, natuals) >>> for n in ns: ... print n 打印出1到10 chain('abc', 'def') imap(), *vs.* map() ifilter()XML 虽然比 JSON 复杂,在 Web 中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作 XML。
# 打开一个 jpg 图像文件,注意路径要改成你自己的: im = Image.open('/Users/michael/test.jpg') # 获得图像尺寸: w, h = im.size # 缩放到50%: im.thumbnail((w//2, h//2)) # 把缩放后的图像用jpeg格式保存: im.save('/Users/michael/thumbnail.jpg', 'jpeg') msg = MIMEText('hello, send by Python...', 'plain', 'utf-8') msg['From'] = _format_addr(u'Python爱好者 <%s>' % from_addr) msg['To'] = _format_addr(u'管理员 <%s>' % to_addr) msg['Subject'] = Header(u'来自SMTP的问候……', 'utf-8').encode()这就是传说中的 ORM 技术:
Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?但是由谁来做这个转换呢?所以 ORM 框架应运而生这个接口就是 WSGI:Web Server Gateway Interface。
find where-to-look criteria what-to-do find /tmp /var/tmp . $HOME -name foo find / -name foo 2>/dev/null find -type f | ag some.\*.txt\$ | xargs tar -rf some.tarxsel -ob # paste text to >The first
--argument that is not an option-argument should be accepted as a delimiter indicating the end of options. Any following arguments should be treated as operands, even if they begin with the-character.For utilities that use operands to represent files to be opened for either reading or writing, the
-operand should be used to mean only standard input (or standard output when it is clear from context that an output file is being specified) or a file named-.“options” (or, historically, “flags”)
When a utility has only a few permissible options, they are sometimes shown individually, as in the example. Utilities with many flags generally show all of the individual flags (that do not take option-arguments) grouped, as in:
utility_name [-abcDxyz][-p arg][operand]utility_name [options][operands]
Utilities with very complex arguments may be shown as follows:
在 Jinja2 模板中,我们用
{{ name }}表示一个需要替换的变量。很多时候,还需要循环、条件判断等指令语句,在 Jinja2 中,用{% ... %}表示指令。- Jinja2, Mako, Cheetah, Django
看起来 A、B 的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核 CPU 呢?最简单的方法是
多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。注意到 consumer 函数是一个 generator(生成器),把一个 consumer 传入 produce 后:- 首先调用
c.next()启动生成器; - 然后,一旦生产了东西,通过
c.send(n)切换到 consumer 执行; - consumer 通过 yield 拿到消息,处理,又通过 yield 把结果传回;
- produce 拿到 consumer 处理的结果,继续生产下一条消息;
- produce 决定不生产了,通过 c.close() 关闭 consumer,整个过程结束。
- 整个流程无锁,由一个线程执行,produce 和 consumer 协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用 Donald Knuth 的一句话总结协程的特点:
“子程序就是协程的一种特例。”
当一个 greenlet 遇到 IO 操作时,比如访问网络,就自动切换到其他的 greenlet,等到 IO 操作完成,再在适当的时候切换回来继续执行。由于 IO 操作非常耗时,经常使程序处于等待状态,有了 gevent 为我们自动切换协程,就保证总有 greenlet 在运行,而不是等待 IO。
- Clojure
@ Clojure 提供了很多函数来操作序列(sequence), 而序列是集合的逻辑视图。很多东西可以被看作序列:Java 集合, Clojure 的集合, 字符串, 流, 文件系统结构以及 XML 树.从已经存在的 clojure 集合来创建新的集合的效率是非常高的,因为这里使用了 persistent data structures 的技术(这对于 clojure 在数据不可更改的情况下,同时要保持代码的高效率是非常重要的)。
'(a b c) (quote (a b c)) hash-map, sorted-map list, vector '(), []When a set is used as a function, it returns the argument if it is in the set and nil otherwise.
Because the Java invocation syntax in Clojure is clean and simple, it is idiomatic to use Java directly, rather than to hide Java behind Lispy wrappers.
defn: define a function- user=>
(load-file "/home/gnat/test.clj") (conj coll item)- this is a set:
#{} conj: conjoin(def visitors (ref #{}))(dosync (commute visitors conj "stu"))
@vistors (deref vistors) user=> (@vistors "stu") "stu" user=> (if (@vistors "stu") (str "true") (str "false")) "true" user=> (if (@vistors "tu") (str "true") (str "false")) "false"Here we’ve got your project’s
README, asrc/directory containing the code, atest/directory, and aproject.cljfile which describes your project to Leiningen. Thesrc/my_stuff/core.cljfile corresponds to themy-stuff.corenamespace.:dependencies [[org.clojure/clojure "1.5.1"]] list in a list, [[],[],[],[]] like this [[<group-id>/<artifact-id> version-number]]>> lein run one This is the foo, and your args are one >> lein run -m my-stuff.core -main good hello main, see you. (-main good) (require 'clojure.string 'clojure.test) vector: (require '[clojure.string :as string]) user=> (string/capitalize "good") "Good" (require 'clojure.string '[clojure.test :as test]) Using other namespaces’ code as though it’s yours: Using other namespaces’ code as though it’s yours: Using other namespaces’ code as though it’s yours: Using other namespaces’ code as though it’s yours: use user=> (split (str (java.util.Date.)) #":") ["Mon Feb 16 22" "55" "56 CST 2015"] (import 'java.util.Date) (Date.) require and then import: (require 'stuff) (import 'stuff.BigWidget)user=> (let [[x y z] v] #_=> (println "x is: " x ", y is: " y ", z is: " z)) x is: 11 , y is: 22 , z is: 33 nil user=> name, namespace, class, #"string as regex" user=> (let [[& x ] v] x) (11 22 33 "string 44") user=> (let [[x & z ] v] z) (22 33 "string 44") user=> (if "true" "true..." "false...") "true..." user=> (if (true? "true") "true..." "false...") "false..."(defun smart-open-line () "Insert an empty line after the current line. Position the cursor at its beginning, according to the current mode." (interactive) (move-end-of-line nil) (newline-and-indent)) (global-set-key [(shift return)] 'smart-open-line)(defun prelude-open-with (arg) "Open visited file in default external program. With a prefix ARG always prompt for command to use." (interactive "P") (when buffer-file-name (shell-command (concat (cond ((and (not arg) (eq system-type 'darwin)) "open") ((and (not arg) (member system-type '(gnu gnu/linux gnu/kfreebsd))) "xdg-open") (t (read-shell-command "Open current file with: "))) " " (shell-quote-argument buffer-file-name)))))(defun copy-file-name-to-clipboard () "Copy the current buffer file name to the clipboard." (interactive) (let ((filename (if (equal major-mode 'dired-mode) default-directory (buffer-file-name)))) (when filename (kill-new filename) (message "Copied buffer file name '%s' to the clipboard." filename))))(defun indent-buffer () "Indent the currently visited buffer." (interactive) (indent-region (point-min) (point-max))) (defun indent-region-or-buffer () "Indent a region if selected, otherwise the whole buffer." (interactive) (save-excursion (if (region-active-p) (progn (indent-region (region-beginning) (region-end)) (message "Indented selected region.")) (progn (indent-buffer) (message "Indented buffer.")))))(defun google () "Google the selected region if any, display a query prompt otherwise." (interactive) (browse-url (concat "http://www.google.com/search?ie=utf-8&oe=utf-8&q=" (url-hexify-string (if mark-active (buffer-substring (region-beginning) (region-end)) (read-string "Google: "))))))(defun indent-defun () "Indent the current defun." (interactive) (save-excursion (mark-defun) (indent-region (region-beginning) (region-end))))(electric-indent-mode +1)(global-set-key (kbd "C-c o") 'open-with) (global-set-key (kbd "C-M-\\") 'indent-region-or-buffer) (global-set-key (kbd "RET") 'newline-and-indent) (global-set-key (kbd "C-c g") 'google) (global-set-key (kbd "C-M-z") 'indent-defun) (global-set-key (kbd "C-c t") 'visit-term-buffer) (global-set-key [(control shift up)] 'move-line-up) (global-set-key [(control shift down)] 'move-line-down)(defun visit-term-buffer () "Create or visit a terminal buffer." (interactive) (if (not (get-buffer "*ansi-term*")) (progn (split-window-sensibly (selected-window)) (other-window 1) (ansi-term (getenv "SHELL"))) (switch-to-buffer-other-window "*ansi-term*")))(defun move-line-up () "Move up the current line." (interactive) (transpose-lines 1) (forward-line -2) (indent-according-to-mode)) (defun move-line-down () "Move down the current line." (interactive) (forward-line 1) (transpose-lines 1) (forward-line -1) (indent-according-to-mode))(require 'paren) (setq show-paren-style 'parenthesis) (show-paren-mode +1)(global-set-key (kbd "C-+") 'text-scale-increase) (global-set-key (kbd "C--") 'text-scale-decrease) (global-set-key (kbd "C-c k") 'kill-other-buffers) (global-set-key (kbd "C-x O") (lambda () (interactive) (other-window -1)))(defun kill-other-buffers () "Kill all buffers but the current one. Don't mess with special buffers." (interactive) (dolist (buffer (buffer-list)) (unless (or (eql buffer (current-buffer)) (not (buffer-file-name buffer))) (kill-buffer buffer))))(require 'dash) (defun prelude-kill-other-buffers () "Kill all buffers but the current one. Doesn't mess with special buffers." (interactive) (-each (->> (buffer-list) (-filter #'buffer-file-name) (--remove (eql (current-buffer) it))) #'kill-buffer))- JavaScript
@ var o = { banana: function () {}, apple: function () {}, default: function () {} } if (o[fruit]) { o[fruit](); } else { o['default'](); } if () {} else {} if () {} else if () {} else {} switch (VAR) { case VAR1: CMD; break; ...; default: CMD; } while () {} for (INIT; TEST; INC) {} do {} while(); try {} catch {} break; continue; lable, break lable; continue lable; number, string, boolean, object, array, function, null, undefined, typeof, instenceof, Object.prototype.toString true, false, &&, ||, !, ===, !==, ==, !="abc".length "abc" .length Number.MAX_VALUE Number.MIN_VALUE var longString = "Long \ long \ long \ string"; // unicode var s = '\u0049'; // "@" s.charAt(0) // char s.charCodeAt(0) // base-10 // Base64 window.btoa('Hellow world') window.atob('...')要将非 ASCII 码字符转为 Base64 编码,必须中间插入一个浏览器转码的环节,再使用这两个方法。
function b64Encode( str ) { return window.btoa(unescape(encodeURIComponent( str ))); } function b64Decode( str ) { return decodeURIComponent(escape(window.atob( str ))); } // 使用方法 b64Encode('你好') // "5L2g5aW9" b64Decode('5L2g5aW9') // "你好"$ echo '你好' | base64 5L2g5aW9 $ echo '5L2g5aW9Cg==' | base64 -d 你好 $ echo '5L2g5aW9Cg' | base64 -d 你好 base64: invalid input # 还要注意换行 $ echo 'good' | base64 Z29vZAo= $ echo -n 'good' | base64 Z29vZA==object
var o = { p: "Hello World" q: "Quit, bye" }; o.p // "Hello World" o["p"] // "Hello World" if ("p" in o) {} // method 1 if ("0" in o) {} // method 2 if (0 in o) {} // method 3 Object.keys(o); // ["p", "q"] delete o.p // true var o = new Object(); o.hasOwnProperty('toString'); // true 'toString' in o // true for (i in o) {console.log(o.i);} // with o.p1 = 1; o.p2 = 2; with (o) { p1 = 3; p2 = 6; } mZ var a = [, , ,]; // legth = 3 not enumerable var b = [undefined, undefined, undefined]; // length = 3, enumerable var c = new Array(3); // length = 3, not enumerable- 数据处理 API 参考手册#md2html
@ - http://whudoc.qiniudn.com/keybr.md?md2html/0/css/aHR0cDovL3Rhbmd6eC5xaW5pdWRuLmNvbS9tYWluLmNzcw==
- http://tangzx.qiniudn.com/main.css –base64 encoding –>
aHR0cDovL3Rhbmd6eC5xaW5pdWRuLmNvbS9tYWluLmNzcw==
- HTTP Redirection
@ <meta HTTP-EQUIV="REFRESH" content="0; url=http://district10.github.io/">countdown:
<!DOCTYPE html> <html> <head> <meta HTTP-EQUIV="REFRESH" content="10; url=http://tangzx.qiniudn.com/post-0105-free-services-that-i-use.html"> <style> .target { color: red; } </style> <script> var target = "Kaggle"; var seconds = 10-1; window.onload = function() { countdown('countdown'); } function countdown(element) { setInterval(function() { var el = document.getElementById(element); if(seconds <= 0) { el.innerHTML = "Redirecting to '<strong class='target'>" + target + "</strong>'..."; return; } var second_text = seconds > 1 ? "seconds" : "second"; el.innerHTML = "Will be redirected to '<strong class='target'>" + target + "</strong>' in " + seconds + " " + second_text + "."; --seconds; }, 1000); } </script> </head> <body> <div id='countdown'>TZX Redirection Page.</div> </body> </html>- MISC
@ fatality
[fə'tæləti]: n. 死亡;宿命;致命性;不幸;灾祸article hr::after { letter-spacing: 0.5em; content: "✼ ✼ ✼"; position: relative; top: -0.4em; } article hr { text-align: center; color: #CCC; }markdown blog:
<a id="id"></a>, then useurl#id, or in tzx-blog, use`@`{.tzx-anchor#id}把「逼格」改爲「屄格」不是「惡意編輯」。把屄格這樣一個氣質低俗的詞柔化、諱飾成「逼格」,造成「其實沒有那麼難聽」的假象,繼續鼓勵人們使用,纔是真正的大惡。因此禁言,誠爲黑白顛倒。做出這一決策的知乎管理員應該爲此感到羞恥。
去掉 QDockWidget 的标题栏
QWidget* titleBar = mPropertyWindow->titleBarWidget(); mPropertyWindow->setTitleBarWidget( new QWidget() ); delete titleBar;QPixmap 与 HBITMAP、HICON 互转
QPixmap::toWinHICON();QPixmap::toWinHBITMAP();QPixmap::fromWinHICON();QPixmap::fromWinHBITMAP();
Qt 编译后移植到其他地方后,qt 寻找库的路径可能出现错误,这时:
在 Qt 的
bin目录下自己建一个qt.conf[Paths] Prefix=C:/dev/qt-4.8.6OpenGL & OpenSceneGraph@void glFrustum( GLdouble left, GLdouble right, GLdouble bottom, GLdouble top, GLdouble nearVal, GLdouble farVal );glFrustumdescribes a perspective matrix that produces a perspective projection. The current matrix (seeglMatrixMode) is multiplied by this matrix and the result replaces the current matrix, as if glMultMatrix were called with the following matrix as its argument:\[\begin{bmatrix} \frac{2nearVal}{right - left} & 0 & A & 0 \\ 0 & \frac{2nearVal}{top - bottom} & B & 0 \\ 0 & 0 & C & 0 \\ 0 & 0 & -1 & 0 \end{bmatrix}\]
\(A = \frac{right + left}{right - left}\) \(B = \frac{top + bottom}{top - bottom}\) \(C = -\frac{farVal + nearVal}{farVal - nearVal}\) \(D = -\frac{2farVal \times nearVal}{farVal - nearVal}\)
Typically, the matrix mode is
GL_PROJECTION, and \((left, bottom, -nearVal)\) and \((right, top, -nearVal)\) specify the points on the near clipping plane that are mapped to the lower left and upper right corners of the window, assuming that the eye is located at (0, 0, 0). - farVal specifies the location of the far clipping plane. Both nearVal and farVal must be positive.Depth buffer precision is affected by the values specified for nearVal and farVal. The greater the ratio of farVal to nearVal is, the less effective the depth buffer will be at distinguishing between surfaces that are near each other. If r = farVal nearVal roughly log 2 r bits of depth buffer precision are lost. Because r approaches infinity as nearVal approaches 0, nearVal must never be set to 0.

A view frustum
- VPN
- the view-plane normal – a normal to the view plane.
- VUV
- the view-up vector – the vector on the view plane that indicates the upward direction.
- VRP
- the viewing reference point – a point located on the view plane, and the origin of the VRC.
- PRP
- the projection reference point – the point where the image is projected from, for parallel projection, the PRP is at infinity.
- VRC
- the viewing-reference coordinate system.
The geometry is defined by a field of view angle (in the ‘y’ direction), as well as an aspect ratio. Further, a set of z-planes define the near and far bounds of the frustum.
// osg::Camera /** Get the orthographic settings of the orthographic projection matrix. * Returns false if matrix is not an orthographic matrix, where parameter * values are undefined.*/ bool getProjectionMatrixAsOrtho(double& left, double& right, double& bottom, double& top, double& zNear, double& zFar) const; /** Get the frustum setting of a perspective projection matrix. * Returns false if matrix is not a perspective matrix, where parameter values * are undefined.*/ bool getProjectionMatrixAsFrustum(double& left, double& right, double& bottom, double& top, double& zNear, double& zFar) const; /** Get the frustum setting of a symmetric perspective projection matrix. * Returns false if matrix is not a perspective matrix, where parameter values * are undefined. Note, if matrix is not a symmetric perspective matrix then * the shear will be lost. Asymmetric matrices occur when stereo, power * walls, caves and reality center display are used. In these configurations * one should use the 'getProjectionMatrixAsFrustum' method instead.*/ bool getProjectionMatrixAsPerspective(double& fovy,double& aspectRatio, double& zNear, double& zFar) const;经过透视投影 (正射投影也一样)变换, 能够把点 从 观察空间(相机坐标系)转换到齐次裁剪空间坐标系(又叫规则观察体(Canonical View Volume)中)。这个转化后的空间体 不仅独立于 把三维场景转换为二维屏幕空间的投影类型(透视、正射),也独立于屏幕的分辨率(Resolution) 以及长宽比(Aspect Ratio).。

齐次裁剪空间坐标系(范围 -1<=x <=1,-1<=y<=1,-1<=z <=1, )是左手坐标系,为什么? 其实也很好理解,如上图 , A和B点经过投影变换后其x坐标是一样的(不再是投影平截体中的那种相对关系), 而近裁剪面上的点的z坐标经过投影变换后变为-1 , 而远裁剪面上的z坐标为1 ,所以齐次裁剪空间坐标系的z轴的正方向正好和相机坐标系中的z轴正方向是相反的。
经过透视投影后,每个顶点的x和y坐标还要除以其z坐标,这个除法是产生透视收缩的方法
osgUtil::PolytopeIntersector // 具体不同算法实现类 osgUtil::IntersectionVisitor //用来遍历节点树的每个节点 osg::Node * mNode; // 你要做相交测试的根节点 osg::ref_ptr<osgUtil::PolytopeIntersector> intersector = new osgUtil::PolytopeIntersector(osgUtil::Intersector::WINDOW, xMin, yMin, xMax, yMax); intersector->setIntersectionLimit(osgUtil::Intersector::LIMIT_ONE_PER_DRAWABLE); osgUtil::IntersectionVisitor iv( intersector.get() ); mRootNode->accept(iv);总结:
- 在
osg::ref_ptr<osg::Node>node = new osg::Node;其中 node 为osg::ref_ptr的对象,而不是指针。 - OSG 中新创建的场景对象建议使用
ref_ptr进行内存分配和管理 - 对于不使用
ref_ptr的对象,引用计数值变得没有意义,并且它无法自动从场景中卸载。 - 新建对象作为函数结果返回时,应该返回
release()。并尽快引入到别的场景中,否则发生内存泄露 - 只有
osg::ref_ptr类来管理 osg 对象的引用计数,其他脱离了(和osg::ref_ptr对象无关的操作)osg::ref_ptr 管理的操作如:赋值等将不会对引用计数产生影响
inline void setNodeMask(NodeMask nm) { _nodeMask = nm; }osg::ref_ptr <osg::MatrixTransform> mat=new osg::MatrixTransform(); osg::Matrix m = osg::Matrix::scale(1.0f,1.0f,1.0f) * osg ::Matrix::translate(osg::Vec3(0,0,10.0f)); mat->setMatrix(m); mat->addChild(node1.get()); osg::ref_ptr<osg::AnimationPathCallback> apcb = new osg::AnimationPathCallback; apcb->setAnimationPath( createAnimationPath(50.0f, 6.0f) ); mat->setUpdateCallback( apcb.get() );//创建一个光照 osg::ref_ptr<osg::Node>createLight(osg::ref_ptr<osg::Node>model) { osg::ComputeBoundsVisitor cbbv; model->accept(cbbv); osg::BoundingBox bb=cbbv.getBoundingBox(); osg::ref_ptr<osg::Light>lt=new osg::Light; lt->setLightNum(0); //设置环境光的颜色 lt->setAmbient(osg::Vec4(1.0f,1.0f,1.0f,1.0f)); osg::ref_ptr<osg::LightSource>ls=new osg::LightSource(); ls->setLight(lt.get()); return ls.get(); }int main() { osg::ref_ptr<osgViewer::Viewer> viewer = new osgViewer::Viewer(); viewer->addEventHandler(new osgViewer::WindowSizeHandler); //创建一个组节点 osg::ref_ptr<osg::Group> root = new osg::Group(); //创建一个阴影节点,并标识接收对象和投影对象 osg::ref_ptr<osgShadow::ShadowedScene> shadowedScene = new osgShadow::ShadowedScene(); shadowedScene->setReceivesShadowTraversalMask(ReceivesShadowTraversalMask); shadowedScene->setCastsShadowTraversalMask(CastsShadowTraversalMask); //创建阴影纹理,使用的是shadowTexture技法 osg::ref_ptr<osgShadow::ShadowTexture> st = new osgShadow::ShadowTexture; osg::ref_ptr<osgShadow::ParallelSplitShadowMap> pss = new osgShadow::ParallelSplitShadowMap; //osg::ref_ptr<osgShadow::ShadowVolume> sv = new osgShadow::ShadowVolume; osg::ref_ptr<osgShadow::MinimalShadowMap> ms = new osgShadow::MinimalShadowMap; osg::ref_ptr<osgShadow::StandardShadowMap> ss = new osgShadow::StandardShadowMap; osg::ref_ptr<osgShadow::SoftShadowMap> softS = new osgShadow::SoftShadowMap; osg::ref_ptr<osgShadow::ViewDependentShadowTechnique> vds = new osgShadow::ViewDependentShadowTechnique; //关联阴影纹理 shadowedScene->setShadowTechnique(softS); //创建一个根节点,并将场景数据、模型赋予节点 osg::ref_ptr<osg::Node> node =createModel(); //添加场景数据并添加光源 shadowedScene->addChild(createLight(node.get())); shadowedScene->addChild(node.get()); root->addChild(shadowedScene.get()); //优化场景数据 osgUtil::Optimizer optimizer ; optimizer.optimize(root.get()) ; viewer->setSceneData(root.get()); viewer->realize(); viewer->run(); return 0 ; }其实简而言之 就是
glOrtho设置相片的大小,glViewport指定相框大小。如果glOrtho指定的相片小了,那么放到同等大小的相框上就相当于放大了。而如果
glOrtho指定的相片大了,放到同等大小的相框上相当于缩小了场景。在
OpenGL中有两个比较重要的投影变换函数,glViewport和glOrtho。glOrtho是创建一个正交平行的视景体。 一般用于物体不会因为离屏幕的远近而产生大小的变换的情况。比如,常用的工程中的制图等。需要比较精确的显示。 而作为它的对立情况,glFrustum则产生一个透视投影。这是一种模拟真是生活中,人们视野观测物体的真实情况。例如:观察两条平行的火车到,在过了很远之后,这两条铁轨是会相交于一处的。还有,离眼睛近的物体看起来大一些,远的物体看起来小一些。glOrtho(left, right, bottom, top, near, far), left 表示视景体左面的坐标,right 表示右面的坐标,bottom 表示下面的,top 表示上面的。这个函数简单理解起来,就是一个物体摆在那里,你怎么去截取他。这里,我们先抛开 glViewport 函数不看。先单独理解 glOrtho 的功能。 假设有一个球体,半径为 1,圆心在 (0, 0, 0),那么,我们设定glOrtho(-1.5, 1.5, -1.5, 1.5, -10, 10);就表示用一个宽高都是 3 的框框把这个球体整个都装了进来。 如果设定glOrtho(0.0, 1.5, -1.5, 1.5, -10, 10);就表示用一个宽是 1.5, 高是 3 的框框把整个球体的右面装进来;如果设定glOrtho(0.0, 1.5, 0.0, 1.5, -10, 10);就表示用一个宽和高都是1.5的框框把球体的右上角装了进来。if(root->getChild(i)->getName().compare("Hello") == 0) { osg::Node * tmp = root->getChild(i); root->removeChild(tmp); *node = tmp; // 在这里tmp 已经析构,因为 只有root引用了hello节点,而在root 节点 // removechild后 tmp的引用计数为0,此时将析构 }refs and see also
- OpenGL 透视投影 齐次裁剪空间 深度缓存 - Emacs 的专栏 - 博客频道 - CSDN.NET
- Qt 小技巧 记录 - Emacs 的专栏 - 博客频道 - CSDN.NET
- glFrustum
- OSG 中 相交测试 模块 工作流程及原理 - Emacs 的专栏 - 博客频道 - CSDN.NET
- OSG 智能指针陷阱 总结 - Emacs 的专栏 - 博客频道 - CSDN.NET
Read more
- Prelude 作者的 Emacs Posts
@ Repeat last command - Emacs Redux
Copy filename to the clipboard - Emacs Redux
Open file in external program - Emacs Redux
Indent region or buffer - Emacs Redux
Network utilities - Emacs Redux
Automatic(electric) indentation - Emacs Redux
Automatic(electric) character pairing - Emacs Redux
Terminal at your fingertips - Emacs Redux
Kill other buffers - Emacs Redux
Go back to previous window - Emacs Redux
Playing with Font Sizes - Emacs Redux
- i3 window manager
@ X-f: fullscreen arrow keys: get focus e, s, w X-e: toggle X-s: stacked X-w: tabbed, X-left, X-right shift r: restart i3 inplace

- The emoji repository has a
CNAMEfile with the domainemoji.muan.co. It is owned by muan, whose User Pages repository has aCNAMEfile with the domainmuan.co. - The Project Pages site at
muan.github.io/emojiredirects tomuan.co/emojiand is also available atemoji.muan.co.
- 我的两个域名都在 DNSPod 控制台 管理。QQ 登录即可。
@ 
2 sites
主机记录 记录类型 记录值 @ A 192.30.252.153 @ A 192.30.252.154 blog CNAME district10.github.io. www CNAME district10.github.io. 域名的 dns 管理在 dnspod,但是域名在 qcloud 管理(tangzhixiong.com)
tangzhixiong.com 到期时间 2019-12-26,60/年
dvorak4tzx.com 2018 年 04 月 27 日
- btSystem 源码文件目录
@ 文件夹 PATH 列表 卷序列号为 00000200 BC08:BFBA D:. ├─data │ └─textures ├─demo │ ├─3rdParty │ │ └─QtPropertyBrowser │ │ ├─canvas_typed │ │ ├─canvas_variant │ │ ├─decoration │ │ ├─demo │ │ │ └─images │ │ ├─extension │ │ ├─object_controller │ │ └─simple │ ├─btExplorerDemo │ ├─btLoggerDemo │ ├─btMainWindowDemo │ ├─btTextureEditorDemo │ ├─IODemo │ ├─JsonReaderDemo │ ├─ModelStructureDemo │ ├─OSGDemo │ ├─QtPropertyBrowserVariantDemo │ ├─RapidJSONDemo │ ├─SignCutterDemo │ ├─SignTransformerDemo │ ├─TextureEditorDemo │ ├─TextureNotationDemo │ └─TheBrowserDemo ├─docs ├─images ├─includes │ ├─OSGDemo │ └─rapidjson │ ├─error │ ├─internal │ └─msinttypes ├─lib │ ├─debug │ └─release ├─notes │ └─images │ ├─deprecated │ ├─icon │ └─material ├─src │ ├─3rdParty │ ├─btGUI │ ├─Global │ ├─Handlers │ ├─IO │ ├─ModelStructure │ ├─Parts │ ├─QtPropertyBrowser │ │ └─images │ ├─SignCutter │ ├─SignLogger │ ├─SignTransformer │ ├─TextureEditor │ ├─TextureNotation │ ├─TheBrowser │ └─Utils └─tryouts └─StackedBoxes └─images
Complex network - Wikipedia, the free encyclopedia
- 一些 LaTeX 模板
@ -
伯尔尼高等专业学院的beamer主题样式 | LaTeX工作室
一个所见即所得的科学公式编辑软件–GNU TeXmacs | LaTeX工作室
LaTeX技巧826:TeXLive的安装与使用-黄正华 | LaTeX工作室
实现TeX的算法:回首编程技术的过去三十年 | LaTeX工作室
LaTeX排版The AWK Programming Language中译本 | LaTeX工作室
中国科学技术大学研究生官网为LaTeX模板正名 | LaTeX工作室
Tikz绘制Android的短信息聊天界面 | LaTeX工作室
- 真爱其实叫牺牲 – 给永远的鼬 (by zak)
@ 修罗之道是什么,它通往何方?在火影忍者中,有如此一人,他便在此道上踏歌而行.在他之后,留下了无尽之血与泪水;在他前方,只有看不见尽头的黑暗;而他红中泛黑的双瞳中,映射出了太多的死亡与破灭。
未来没有救赎,只有灭亡,抱此觉悟,宇智波鼬——即使在宇智波这个原本就自悲剧中诞生的家族之中也是最具悲剧色彩的男人, 背负了太多诅咒与怨恨, 在名为终结的黑色的华尔兹舞曲中艰难而孤傲的独舞.
其实,他只是一位兄长,他只想保护自己的弟弟,就算被自己的弟弟憎恨也无所谓,就算被弟弟杀掉也无所谓。“我愚蠢的弟弟啊,如果你想杀我的话,就憎我恨我吧,不断地逃,不断地逃只是为了活着而活着,然后,等你哪一天得到了和我相同的眼睛,就来到我面前吧。”他只想让弟弟活下去,便只得噙着泪水这样冷酷的说道,在乱世之中,这是唯一可以让弟弟强大起来的办法—给予他杀死自己的目标,让他把仇恨全部发泄到自己的身上。
其实,他只是一名忍者,忍者本来就是活在黑暗中的,鼬更把这一忍道贯彻的淋漓尽致。自我牺牲是忍者的本分,这便是鼬的信念。他所渴望的,是村子的兴盛,是整个忍者世界的和平,也许我们看来这个词过于恶俗,但鼬却义无反顾的为之奋斗。他亲手为自己的一族落下了帷幕,是为了避免更惨痛的战争,所谓战争…就一定伴随着双方的死亡伤病和痛苦… 但鼬宁愿独自吞下着苦果,他这么做了。在那个月圆之夜,他亲自动手将自己的族人全部抹杀,唯独他的弟弟,他下不了手。然后,为了不让弟弟仇恨自己的村子,他说了那样的话,他宁愿一个人背负弟弟所有的仇恨。
鼬,这个顶级的幻术高手,给自己的弟弟制造了一个最大的幻术,单纯的佐助,自以为自己的写轮眼能看穿一切幻术,但是,他的眼睛,没能看破鼬的任何真相,鼬所制造的幻象,他一个都没能看穿。“人都是依靠自己的知识和认识又被其束缚的活着的,还将其称之为现实,但知识和认识是暧昧不清的东西,那个现实,也许只是镜花水月而已,人都是活在自己的意识世界里,你不这样认为吗?”面对鼬的质问,这个愚蠢的弟弟依然浑然没有觉察到,自己的哥哥是如何的爱自己,被仇恨吞噬的佐助,只想尽早杀掉自己的大哥,报仇雪恨。终于,在这一天,他成功了。
鼬是故意让佐助杀掉自己的,他只想让自己的弟弟活下去,便只能牺牲自己。为了保护自己的村子,他也只能牺牲自己,作为一介罪犯,一个叛徒,而悲惨地死去。他时刻不忘自己的弟弟,自己的村子,甚至整个忍者世界,为了成全大义,只有牺牲自己。
是鼬告诉了我们,自我牺牲才是真爱,这个冷酷的男人一生都没有哭过,只是在灭族的那一天晚上,面对自己的弟弟,落下了悲痛的泪水,没有人知道,这幅冰冷的外表下,是一颗温暖的心,充满爱的心。
他死后,没有认为他立碑立传,甚至在许多人看来是大快人心,只有老天为之动容,那淅淅沥沥的雨,或许就是天在哭泣吧!只有他曾经的敌人,斑,给了他最恰当的评价。他对佐助说道:“鼬他,杀害上司,杀害朋友,杀害恋人,杀害父亲,杀害母亲,唯独没有对自己的弟弟动手。心中流淌着血一般的泪水,将自己的全部感情抹杀的男人,却无法对你下手,知道为什么吗·········因为在他心中,你的性命比村子的安危更重要!”
“宁愿舍弃名誉而污名缠身,宁愿放弃爱而选择背负仇恨,但即便如此,鼬还是含着笑离开了人世。”
鼬笑着离开了,了无牵挂的离开了,只留下了唯一的遗言—
“原谅我,
佐助,
这是
最后一次了
- 是命运么,教我如何相信 – 写给鸣人和佐助 (by zak)
@ 一个伴随了我们十年之久的故事,一种在爱与恨中挣扎却无比坚毅的成长,一段用努
力和汗水去赢得认可的历程。火影的故事就这样铺陈开来,伴随着我们流逝的青春,
刻下磨不灭的印记。——题记
两个人,两个完全不同的人。
鸣人,是那样的炽烈,像骄阳一般,温暖着每一个人,影响着每一个人。冲天的金黄的头发,纯粹的蓝色眼眸,带着不变的自信,踏上梦想之路,一步一步跌跌撞撞的走来。阳光下,他静静站立,脸上的笑容,满载着难以言明的自信,灿烂的荡漾开来,将所有的失落,所有的泪水统统抛下。谁能想到,他曾经地多么的寂寞。小小的心灵又怎能承受得住那么都不屑的眼神,明明是想证明自己的,又为什么总是失败?树下的秋千上,他默默的坐着,低垂的头掩饰不住的伤心,与周围同学们毕业的欣喜构成鲜明的对比。与生俱来的自信与乐观又怎甘心如此弱小的活下去,所以他想当火影,为此奋勇前进。他是天生的逐梦者,会为梦想披荆斩棘。
而佐助,相对于鸣人而言,就是一块寒冰,冷得让人难以靠近。苍白的脸上看不到任何表情,黑色的眼睛像一潭深不见底的水,你永远也猜不清他在想什么。很多时候,他只是静静的站着,静静的坐着,却让人感到那么的寂寞。他曾经也是个爱笑的孩子啊,谁能想到只是一瞬之间,所有的一切就消失殆尽。快乐的时光再也追不回,曾经的幸福再也找不到,于是憎恨便滋生开,像是罂粟花,绚丽却有毒。他是真正的复仇者,仇恨是他不能释怀的心结,力量才是他真正追求的东西。
时间真是个奇怪的东西,默默的流逝,却像可以海浪般席卷一切。
佐助的离开,是鸣人心中的痛。他无数次去追寻,却又无能为力。或许鸣人和佐助的那一战,是两人生命线猛烈的撞击,火花四溅,编织出拭不去的羁绊。
时光流逝,将羁绊编织成命运。
佐助杀了大蛇丸,得到了想要的力量,鸣人在自来也死后成为了预言之子;佐助杀了鼬,本以为复了仇,却发现原来一切都只是个阴谋,是个错误;鸣人拯救了村子,成为了英雄,团藏的阴谋却恰巧袭来。成长的路注定不平坦。佐助要向木叶报仇,而鸣人想借机会拯救佐助。两个人已经站到了对立的面上,下次相遇,会是难以挽回的命运吗?
“曾经六道真人宣扬忍宗,将世界引导向和平 ,理想为完成之时,他的大限即将来临。六道仙人见忍宗的力量和意志托付给两个孩子。哥哥具有仙人之“眼”,于是传授给他查克拉的力量和精神力。弟弟天生具有仙人之“肉体“,所以传授给他生命力和身体能量。因为领悟到和平必须要有爱……仙人在弥留之际,不得不决定继任者……但是就是那个决定导致了永恒持续的憎恨诅咒……仙人觉得比起追求力量的哥哥……追求爱的弟弟才是最合适的继任者。作为长男认为自己理所应当继任的 哥哥无法认同仙人的选择……因为憎恨他向弟弟宣战。时间流逝,血缘逐渐疏远,两兄弟的子孙依旧持续战争。哥哥的子孙被称为宇智波,弟弟的子孙被称为千手……我宇智波斑和初代火影千手柱间之间的战斗,也是命运。”(选自火影漫画462集斑所说的话)
鸣人继承了火的意志,而佐助是宇智波一族的后代。
这是宿命吗?
“千手和宇智波,火的意志和憎恨,鸣人和佐助。你们两个将成为命运选中的另一对兄弟”。”(选自火影漫画462集斑所说的话)
真是宿命吗?
我不是个相信宿命的人,更不相信宿命可以决定一切。
还记得当鸣人还被大家歧视时,他努力的要得到大家的认可,他成功了;当鸣人还是个吊车尾时,他努力要变强,他成功了;中忍考试时,他对战信命的宁次,他胜利了。因此他一次一次对命运反抗,正是因为这种反抗,他才走到了今天。难道这一切都只不过是宿命的安排?教我如何相信,如何相信宿命可以强大到让人无法反抗?难道鸣人的执着,鸣人的坚持,佐助的偏执,佐助的憎恨,都不过是上天安排的一场游戏?我不相信!绝不!
宿命么,这么虚无缥缈的东西,不体会过又怎能知道,不反抗又怎么知道不可以?
我不知道最后的结局会怎样。但我相信,就算是宿命,鸣人和佐助也会是破除宿命的人。
所以,请期待下去吧。静静地,期待吧…………
- 军区管辖范围:
@ - 北京军区: 北京、河北、内蒙古、山西 俄罗斯、蒙古
- 沈阳军区: 辽宁、吉林、黑龙江 俄罗斯、朝鲜
- 济南军区: 山东、河南 黄海对面
- 南京军区: 江苏、安徽、上海、浙江、江西、福建黄海、东海对面
- 兰州军区: 甘肃、青海、陕西、宁夏、新疆 蒙古
- 成都军区: 四川、重庆、贵州、云南、西藏印度、越南、缅甸
- 广州军区: 广东、广西、海南、湖南、湖北越南、南海对面
P.L.A.是中国人民解放军(People’s Liberation Army)的英文简称。中国人民解放军是中国军事力量的主要组成部分,是巩固人民民主专政的坚强柱石、保卫社会主义祖国的钢铁长城和建设社会主义的重要力量。中国人民解放军现役总兵力为200万人(截至2015年底)
Dual-role keys@It is possible to use (with some utility software) one same key both as a normal key and as a modifier.
For example, you can use the space bar both as a normal Space bar and as a Shift. Intuitively, it’ll be a Space when you want a whitespace, and a Shift when you want it to act as a shift. I.e. when you simply press and release it, it is the usual space, but when you press other keys, say X, Y and Z, while holding down the space, then they will be treated as ⇧ Shift plus X, Y and Z.
The above example is known as “SandS”, standing for “Space and Shift” in Japan. But any number of any combinations are possible.
To press shift+space in the previous example, you need in addition to a space/shift dual role key, one of (a) another space/shift key, (b) a usual shift, or (c) a usual space key.
refs and see also
Fleshlight - Wikipedia, the free encyclopedia
- Image Engine
@ AMERICAN SNIPER TEENAGE MUTANT NINJA TURTLES ELYSIUM LONE SURVIVOR : <iframe src="https://player.vimeo.com/video/90177922" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe> R.I.P.D. : <iframe src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://player.vimeo.com/video/90173618" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe> ZERO DARK THIRTY : <iframe src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://player.vimeo.com/video/91452356" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe> WHITE HOUSE DOWN : <iframe src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://player.vimeo.com/video/91453702" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe> SAFE HOUSE : <iframe src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://player.vimeo.com/video/92181438" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe> THE THING : <iframe src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://player.vimeo.com/video/92187878" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe> IMMORTALS : <iframe src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://player.vimeo.com/video/95316985" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe> DISTRICT 9 : <iframe src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://player.vimeo.com/video/95324453" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe>split to images@#!/bin/bash convert img.jpg -crop 100x100 +repage +adjoin l0-%d.jpg- A python script to speed up the rendering process of Hexo 3.
@ 程序还是越写越好的。
#!/usr/bin/python2 ''' SYNOPSIS: $ python speedup.py -f FILE or $ python speedup.py -d DIR ''' import sys, os, getopt TARGET_TYPE = [".md", ".markdown"] def process_file(path): ''' Process a file. ''' line = "" quote_flag = False line_list = [] with open(path) as f: while True: line = f.readline() if line == "": break if line.startswith("```"): quote_flag = not quote_flag if line.strip()=="```" and quote_flag: line = "``` plain\r\n" line_list.append(line) with open(path, 'w+') as f: f.writelines(line_list) def process_dir(path): ''' Process a directory. ''' file_list = [] files = os.listdir(path) for file in files: file = os.path.join(path, file) root, ext = os.path.splitext(os.path.basename(file)) if os.path.isfile(file) and ext in TARGET_TYPE: process_file(file) def main(): if len(sys.argv) < 2: print "Arguments should be at least 2." print "python speedup.py -f [FILE]" print "python speedup.py -d [DIRECTORY]" exit(1) try: opts, args = getopt.getopt(sys.argv[1:], "f:d:", ["file=", "directory="]) for arg, value in opts: if arg in ('-f', '--file'): root, ext = os.path.basename(value) if ext in 'TARGET_TYPE': process_file(value) elif arg in ('-d', '--directory'): process_dir(value) else: print "Argument error. %s" % arg exit(1) except getopt.GetoptError as e: print e exit(1) if __name__ == '__main__': main()Three Virtues@Perl 语言的发明人 Larry Wall 说,好的程序员有 3 种美德: 懒惰、急躁和傲慢(Laziness, Impatience and hubris)。
According to Larry Wall, the original author of the Perl programming language, there are three great virtues of a programmer; Laziness, Impatience and Hubris:
- Laziness: The quality that makes you go to great effort to reduce overall energy expenditure. It makes you write labor-saving programs that other people will find useful and document what you wrote so you don’t have to answer so many questions about it.
- Impatience: The anger you feel when the computer is being lazy. This makes you write programs that don’t just react to your needs, but actually anticipate them. Or at least pretend to.
- Hubris: The quality that makes you write (and maintain) programs that other people won’t want to say bad things about.
refs and see also
- 当一个人不打算再骂一个人,扭头就走的时候,情分就尽了。
@ 为什么整部《水浒》里,最有影响力的老虎要被武松打死呢?因为这事儿拼的不是武力。李逵杀虎,靠的是武力。所以李逵打死的老虎都不算老虎,和虾蟹没有太大区别。正因为不算老虎,才能一下杀四个。武松杀老虎,只能有一次,只能有一个。而且,必须赤手空拳。景阳冈上的老虎,象征自然的神威,象征流俗都不得不畏惧的法则,要对抗这种老虎,唯有最纯粹的人才可以。
因为你会觉得,真正用心去做这件事情是不值的,是很白痴的。你有聪明才智,如果你珍惜它,就把它用到该用的地方,而不是被别人肆意地鄙弃。
我喜欢实打实的东西。要考试,那么就拼智商,拼记忆力,拼逻辑能力,甚至拼写字快—— 总得有一个标尺。但你知道,很多课程是没有的。你考得好与坏跟你从这门课里学到了什么没有丝毫联系。那还考个——用四川话说,考个锤子啊。既然考试,那就一鞭一条痕,一掴一掌血。
worktile@- Roman numerals - Wikipedia, the free encyclopedia
@ Symbol Value I 1 V 5 X 10 L 50 C 100 D 500 M 1,000
bible(ai) 和 babel(e) 这两个单词的发音好像啊……
specifics 和 specifies 的区别在哪里?
indefinite v.s. infinite
单词 音标 解释 chillax [tʃɪˈlæks]淡定 craftsmanship ['kræftsmənʃɪp]技艺 czar [zɑː]沙皇 designated ['dɛzɪg,netɪd]特指的 etymology [,ɛtɪ'mɑlədʒi]语源学 hypocrite ['hɪpə'krɪt]伪君子;伪善者 loathing ['loðɪŋ]嫌恶 mandate ['mændet]委托管理 paranoid ['pærənɔɪd]偏执狂患者 predecessor ['prɛdəsɛsɚ]前辈 revulsion [rɪ'vʌlʃən]强烈反感 silhouette [,sɪlu'ɛt]轮廓,剪影 specific [spɪ'sɪfɪk]特定的 specify ['spɛsɪfaɪ]详细说明 sublime [sə'blaɪm]崇高 successor [sək'sɛsɚ]继承者 survivalism [sə'vaɪv(ə)lɪz(ə)m]生存第一主义 verbatim [vɝ'betɪm]逐字地 xenophobia [,zɛnə'fobɪə]对外国人的畏惧和憎恨 - Roman numerals - Wikipedia, the free encyclopedia
1001 = 7 * 11 * 13
- Code Rush
@

ASCII Table
- 维基百科的音标
@ 照理说我不需要额外整理音标的内容,因为我很仔细地看过《赖世雄美语音标》,音标基本都会。但不幸地是我不知道音标标的是哪一种(美语、英语?),所以还是整理一下维基的音标,这样以后会更清楚上面查到的东西的读音。
Constants
IPA Examples bbuy, cab ddye, cad, do ðthy, breathe, father dʒgiant, badge, jam ffan, caff, phi ɡ(ɡ)guy, bag hhigh, ahead hwwhy jyes, hallelujah ksky, crack llie, sly, gal mmy, smile, cam nnigh, snide, can ŋsang, sink, singer θthigh, math ppie, spy, cap rrye, try, very ssigh, mass ʃshy, cash, emotion ttie, sty, cat, atom tʃchina, catch vvie, have wwye, swine zzoo, has ʒequation, pleasure, vision, beige Marginal consonants
IPA Examples xugh, loch, Chanukah ʔuh-oh /ˈʔʌʔoʊ/ ˜bon vivant /ˌbɒ̃ viːˈvɒ̃/ IPA Full vowels IPA … followed by R ɑːPALM, father, bra ɑːrSTART, bard, barn, snarl, star ɒLOT, pod, John ɒrmoral, forage æTRAP, pad, ban ærbarrow, marry aɪPRICE, ride, file, fine, pie aɪərIreland, hire (= /aɪr/) — — aɪ.ərhigher, buyer aʊMOUTH, loud, foul, down, how aʊərflour (= /aʊr/) — — aʊ.ərflower ɛDRESS, bet, fell, men ɛrerror, merry eɪFACE, made, fail, vein, pay ɛərSQUARE, mare, scarce, cairn, Mary (= /eɪr/) — — eɪ.ərlayer (one who lays) ɪKIT, lid, fill, bin ɪrmirror, Sirius iːFLEECE, seed, feel, mean, sea ɪərNEAR, beard, fierce, serious (= /iːr/) — — iː.ərfreer ɔːTHOUGHT, Maud, dawn, fall, straw ɔːrNORTH, born, war, Laura — — ɔː.ərsawer ɔɪCHOICE, void, foil, coin, boy ɔɪərcoir (= /ɔɪr/) — — ɔɪ.əremployer oʊGOAT, code, foal, bone, go ɔərFORCE, more, boar, oral (= /oʊr/) — — oʊ.ərmower ʊFOOT, good, full, woman ʊrcourier uːGOOSE, food, fool, soon, chew, do ʊərboor, moor, tourist (= /uːr/) — — uː.ərtruer juːcute, mule, puny, beauty, huge, you, tune jʊərcure (= /juːr/) — — juː.ərfewer ʌSTRUT, bud, dull, gun ɜːrNURSE, word, girl, fern, furry — — ʌrhurry, nourish (in the UK) Reduced Vowels
IPA Reduced vowels IPA Reduced Vowels ᵻroses, enough (either /ɪ/or/ə/)ᵿbeautiful, curriculum ( [jᵿ]) (either/ʊ/or/ə/)ɵomission (either /oʊ/or/ə/)usituation (either /ʊ/or/uː/)əRosa’s, a mission, quiet, focus ərLETTER, perceive iHAPPY, serious (either /ɪ/or/i/)əlbottle (either [əl]or[l̩])ənbutton (either [ən]or[n̩])əmrhythm (either [əm]or[m̩])Stress & Syllabification
- intonation
/ˌɪntɵˈneɪʃən/ - Mikey
/ˈmaɪki/, Myki/ˈmaɪ.kiː/
refs and see also
- intonation
- 《影响力》
@ - Weapons of Influence: Perceptual Contrast | 对比原理
Everything should be made as simple as possible, but not simpler.
— ALBERT E INSTEIN
Virtually all of this mothering is triggered by one thing: the “cheep-cheep” sound of young turkey chicks. Other identifying features of the chicks, such as their smell, touch, or appearance, seem to play minor roles in the mothering process. If a chick makes the “cheep-cheep” noise, its mother will care for it; if not, the mother will ignore or sometimes kill it.
When, however, the same stuffed replica carried inside it a small recorder that played the “cheep-cheep” sound of baby turkeys, the mother not only accepted the oncoming polecat but gathered it under- neath her. When the machine was turned off, the polecat model again drew a vicious attack.
How ridiculous a female turkey seems under these circumstances: She will embrace a natural enemy just because it goes “cheep-cheep,” and she will mistreat or murder one of her own chicks just because it does not. She looks like an automaton whose maternal instincts are under the automatic control of that single sound.
when the situation calls for mothering, the maternal-behavior tape gets played. Click and the appropriate tape is activated; whirr and out rolls the standard sequence of behaviors.
Clever use of perceptual contrast is by no means confined to clothiers. I came across a technique that engaged the contrast principle while I was investigating, undercover, the compliance tactics of real-estate companies. To “learn the ropes,” I was accompanying a company realty salesman on a weekend of showing houses to prospective home buyers.
The salesman—we can call him Phil—was to give me tips to help me through my break-in period. One thing I quickly noticed was that whenever Phil began showing a new set of customers potential buys, he would start with a couple of undesirable houses. I asked him about it, and he laughed. They were what he called “setup” properties.
Sharon may be failing chemistry, but she gets an “A” in psychology.
- Reciprocation: The Old Give and Take…and Take | 互惠原理
Pay every debt, as if God wrote the bill.
— RALPH WALDOE MERSON
So typical is it for indebtedness to accompany the receipt of such things that a term like “much obliged” has become a synonym for “thank you,” not only in the English language but in others as well.
It quickly became clear to the Society that it had a considerable public-relations problem. The people being asked for contributions did not like the way the members looked, dressed, or acted.
The Krishnas’ resolution was brilliant. They switched to a fund-raising tactic that made it unnecessary for target persons to have positive feel- ings toward the fund-raisers. They began to employ a donation-request procedure that engaged the rule for reciprocation, which, as demon- strated by the Regan study, is strong enough to overcome the factor of dislike for the requester. The new strategy still involves the solicitation of contributions in public places with much pedestrian traffic (airports are a favorite), but now, before a donation is requested, the target person is given a “gift”—a book (usually the Bhagavad Gita), the Back to Godhead
magazine of the Society, or, in the most cost-effective version, a flower. The unsuspecting passerby who suddenly finds a flower pressed into his hands or pinned to his jacket is under no circumstances allowed to give it back, even if he asserts that he does not want it. “No, it is our gift to you,” says the solicitor, refusing to accept it.
The Rule Enforces Uninvited Debts The Rule Can Trigger Unfair Exchanges
The Old Give and Take…and Take…
RECIPROCAL CONCESSIONS | 相互退让
At first glance, our fortunes in such a situation would appear dismal. We could comply with the requester’s wish and, in so doing, succumb to the reciprocity rule. Or, we could refuse to comply and thereby suffer the brunt of the rule’s force upon our deeply conditioned feelings of fairness and obligation. Surrender or suffer heavy casualties. Cheerless prospects indeed.
- Commitment and Consistency: Hobgoblins of the Mind | 承偌和一致
It is easier to resist at the beginning than at the end.
— LEONARDO DA VINCI
COMMITMENT IS THE KEY
- Social Proof: Truths Are Us
- Liking: The Friendly Thief
- Authority: Directed Deference
- Scarcity: The Rule of the Few
refs and see also
RapidJson@// 把整个文件读入buffer FILE* fp = fopen("test.json", "r"); fseek(fp, 0, SEEK_END); size_t filesize = (size_t)ftell(fp); fseek(fp, 0, SEEK_SET); char* buffer = (char*)malloc(filesize + 1); size_t readLength = fread(buffer, 1, filesize, fp); buffer[readLength] = '\0'; fclose(fp);In situ是一个拉丁文片语,字面上的意思是指「现场」、「在位置」。在许多不同语境中,它描述一个事件发生的位置,意指「本地」、「现场」、「在处所」、「就位」。 …… (在计算机科学中)一个算法若称为原位算法,或在位算法,是指执行该算法所需的额外内存空间是O(1)的,换句话说,无论输入大小都只需要常数空间。例如,堆排序是一个原位排序算法。在 C++11 中这称为转移赋值操作(move assignment operator)。由于 RapidJSON 支持 C++03,它在赋值操作采用转移语意,其它修改形函数如
AddMember(),PushBack()也采用转移语意。QRectF QGraphicsItem::boundingRect () const@This pure virtual function defines the outer bounds of the item as a rectangle; all painting must be restricted to inside an item’s bounding rect.
QGraphicsViewuses this to determine whether the item requires redrawing.Although the item’s shape can be arbitrary, the bounding rect is always rectangular, and it is unaffected by the items’ transformation.
If you want to change the item’s bounding rectangle, you must first call
prepareGeometryChange(). This notifies the scene of the imminent change, so that its can update its item geometry index; otherwise, the scene will be unaware of the item’s new geometry, and the results are undefined (typically, rendering artifacts are left around in the view).Reimplement this function to let
QGraphicsViewdetermine what parts of the widget, if any, need to be redrawn.Note: For shapes that paint an outline / stroke, it is important to include half the pen width in the bounding rect. It is not necessary to compensate for antialiasing, though.
Example:
QRectF CircleItem::boundingRect() const { qreal penWidth = 1; return QRectF( -radius - penWidth / 2, -radius - penWidth / 2, diameter + penWidth, diameter + penWidth ); }QRectF Robot::boundingRect() const { return QRectF(); }QObject@Error 1 error C2248: 'QObject::QObject' : cannot access private member declared in class 'QObject' ModelLane.h 23 1 ModelStructureQObject从设计上不可拷贝,所以这样的代码是错误的:class UrObject : public QObject { ... }; // 没有自己实现 = 运算符 QList<UrObject> objects; // Then, WRONG!作为一种折衷你可以换成指针:
QList<UrObject *> ojebcts;See
载入配置文件 fallback@const char *paths[] = { "data/sample.json", // possible path "bin/data/sample.json", // possible path }; FILE *fp = 0; for ( size_t i = 0; i < sizeof(paths) / sizeof(paths); ++i ) { fp = fopen(filename_ = paths[i], "rb"); if (fp) { break; } } ASSERT_TRUE(fp != 0); fseek(fp, 0, SEEK_END); length_ = (size_t)ftell(fp); fseek(fp, 0, SEEK_SET); json_ = (char*)malloc(length_ + 1); ASSERT_EQ(length_, fread(json_, 1, length_, fp)); json_[length_] = '\0'; fclose(fp);忽略掉一个参数,可以用 void:
void(argv);,也可以在函数定义的时候int main(int, char**),甚至int main()。 Qt 里有Q_UNUSED(object)宏。- 如何 base64 编码一个图片?
@ 可以用 Firefox 浏览器,在 F12 下面,对着图片右键,可以“Copy Image Data-URL”,就复制到了 Base64 编码的图片。
- idiomatic
[,ɪdɪə'mætɪk](惯用的;符合语言习惯的;通顺的)@ #!/bin/perl foreach (1..10) { print "Iteration number $_.\n\n"; print "Please choose: last, next, redo, or none of the above? "; chomp(my $choice = <STDIN>); print "\n"; last if $choice =~ /last/i; next if $choice =~ /next/i; redo if $choice =~ /redo/i; print "That wasn't any of the choice... onward!\n\n"; }# d: debug, e: evaluate (one liner), l: ?process line ending $ perl -del # Perl REPL- Flappy Bird - Wikipedia, the free encyclopedia
@ flappy,
['flæpi], adj. 飞扬的- bash, cmd
@ $ set KEY=val # windows $ setenv KEY val # csh $ export KEY=val # bash#!/bin/bash FILES=./markdown/* for fin in $FILES do fout=${fin/markdown/articles} # path # smart fout=${fout/\.markdown/.html} # extension # smart pandoc $fin -t html5 -o $fout \ --toc --smart --standalone \ --template=template done上面的脚本很巧妙,我从来没想过可以用正则表达式。那不是正则。- VimFx
@ o ; address bar O ; search bar p ; paste and go, ; 和地址栏的 Bing 结合意味着你可以随时 ; 选择文字,复制,然后 p 搜索。 P ; paste and go in new window yy ; yank tab url g/ ; links only / ; normal text search gJ, gK, gw ; move tab left, right, to new window g0, g^, g$ ; move to tab (first, first non-pinned, last) gp ; pin tab gt, gT ; next, previous tab (感觉 J,K 用起来是反的,果断抛弃) x, X ; close, restore gxa, gx$ ; close multiple tabs s, sa ; stop loading最重要的是
?可以查看帮助。CMD Line@int i; for(i = 0; i < argc; ++i) { if(argv[i]) commandLine.push_back(argv[i]); // Reads each argument from the // command line and pushes it on the vector else return i; } return i; string CommandLine::GetNextWord() { if((int)pos < (int)commandLine.size()) return commandLine[pos++]; // Retrieves the next word from the command line vector. else // State is maintained by 'pos' return ""; }enum ERRTYPE {NOERROR, WARNING, FATAL}; class VCOption { public: string vc; bool space; ERRTYPE error; }; #include <string> using namespace std; #include "VCOption.h" /* This class simply encapsulates * the three string items we'd like to return. */ class ReturnItem { public: ReturnItem() {bestMatch = ""; bestMap = ""; remainingString = ""; space = true; error=NOERROR;} ~ReturnItem() {} ; // ReturnItem& operator=(ReturnItem const *rhs); string bestMatch, bestMap, remainingString; bool space; ERRTYPE error; }; #define CCSTATE (0) #define VCSTATE (1) #define LINESIZE (80) class Input { public: Input() {}; ~Input() {}; int ReadInputFile(char const *fileName); int CreatePairsFromCode(); ReturnItem BestMapping(string &origOpt); private: bool AddPair(string other, string vc, bool space = true); bool AddPair(string other, string vc, ERRTYPE error); vector<pair<string, VCOption> > optionPairs; }; #include <fstream> #include <iostream> #include <string> #include "Input.h" #include "ReturnItem.h" #include "VCOption.h" /* Function Name: AddPair Parameters: string other - This is the switch from the "other" compiler. string vc - This is the switch that 'other' maps to on VC. Return Value: true Actions: This pushes the pair <other, vc> onto the vector optionPairs. */ bool Input::AddPair(string other, string vc, bool space) { VCOption vcOption; vcOption.space = space; vcOption.vc = vc; vcOption.error = NOERROR; optionPairs.push_back(make_pair(other, vcOption)); return true; } bool Input::AddPair(string other, string vc, ERRTYPE error) { VCOption vcOption; vcOption.space = true; vcOption.vc = vc; vcOption.error = error; optionPairs.push_back(make_pair(other, vcOption)); return true; } /* Function Name: ReadInputFile Parameters: char const *fileName - The name of the input file we will be reading from. Return Value: -1 if there is an error (unspecified what the error is) 1 if the function executes successfully Actions: The Input::optionPairs vector is filled with the pairings as specified by the input file named fileName. */ int Input::ReadInputFile(char const *fileName) { if(fileName == NULL) return -1; string ccOption, vcOption; string option; char temp[LINESIZE]; ifstream inputFile(fileName); if(!inputFile) { cerr << "No file named : " << fileName << endl; return -1; } bool spaceState = false; int state = CCSTATE; while(inputFile >> option) { switch(state) { case CCSTATE: if(option == "@@@") { inputFile.getline(temp, LINESIZE); break; } if(option == "~~~") { return 1; } if(option == "***") { spaceState = false; state = VCSTATE; } else { if(spaceState) { ccOption += " "; } spaceState = true; ccOption += option; } break; case VCSTATE: if(option == "!!!") { spaceState = false; state = CCSTATE; AddPair(ccOption, vcOption); ccOption = ""; vcOption = ""; } else if(option == "###") { spaceState = false; state = CCSTATE; AddPair(ccOption, vcOption, false); ccOption = ""; vcOption = ""; } else if(option == "EEE") { spaceState = false; state = CCSTATE; AddPair(ccOption, vcOption, FATAL); ccOption = ""; vcOption = ""; } else if(option == "^^^") { spaceState = false; state = CCSTATE; AddPair(ccOption, vcOption, WARNING); ccOption = ""; vcOption = ""; } else { if(spaceState) { vcOption += " "; } spaceState = true; vcOption += option; } break; default: cerr << "Invalid State" << endl; return -1; } } return 1; } // This code here just loads the optionPairs from the code. It acts like ReadInputFile. // This is only called if you define CCMEMORY int Input::CreatePairsFromCode() { AddPair("-Wall", "/Wall"); AddPair("-O2", "/O2"); AddPair("-c", "/c"); AddPair("-S", "/s"); AddPair("-E", "/EP"); /* $ ./ccWrapper.exe test -E cl test /EP ... */ AddPair("-o", "/Fe", false); AddPair("--help", "/?"); AddPair("-ansi", "/Za"); AddPair("-funsigned-char", "/J"); AddPair("-pedantic", "/Za"); AddPair("-pedantic-errors", "/Za"); AddPair("-w", "/W0"); AddPair("-ggdb", "/Zi"); AddPair("-gstabs", "/Zi"); AddPair("-gstabs+", "/Zi"); AddPair("-gcoff", "/Zi"); AddPair("-gxcoff", "/Zi"); AddPair("-O0", "/Od"); AddPair("-O1", "/O2"); AddPair("-O2", "/O2"); AddPair("-O3", "/Ox"); AddPair("-Os", "/O1"); AddPair("-float-store", "/Op"); AddPair("-fno-default-inline", "/Ob0"); AddPair("-fomit-frame-pointer", "/Oy"); AddPair("-fno-inline", "/Ob0"); AddPair("-finline-functions", "/Ob2"); AddPair("-include", "/FI"); AddPair("-nostdinc", "/X" ); AddPair("-undef", "/u" ); AddPair("-C", "/C" ); AddPair("-P", "/P" ); AddPair("-D", "/D"); AddPair("-U", "/U"); AddPair("-nodefaultlibs", "/link /NODEFAULTLIB"); AddPair("-nostdlib", "/link /NODEFAULTLIB"); AddPair("-I", "/I"); AddPair("-L", "/link /LIBPATH:"); AddPair("-fpack-struct", "/Zp1"); AddPair("-fstack-check", "/GS"); return 1; } /* Function Name: BestMapping Parameters: string &origOpt - The switch to be mapped from. Return Value: ReturnItem This ReturnItem class contains the .bestMatch string which is the best matching switch. The .bestMap string is the VC switch that .bestMatch maps too. The .remainingString is what is left of the origOpt string after you remove the .bestMatch string. Actions: This method finds the switch that best matches origOpt. If there is more than one switch that matches origOpt then the longest match is selected. */ ReturnItem Input::BestMapping(string &origOpt) { ReturnItem bestItem; string currentStr; string::size_type idx; vector<pair<string, VCOption> >::iterator iterOpt, endOpt; endOpt = optionPairs.end(); bestItem.remainingString = origOpt; for(iterOpt = optionPairs.begin(); iterOpt != endOpt; ++iterOpt) { currentStr = iterOpt->first; idx = origOpt.find(currentStr, 0); if(idx == 0) { if(currentStr.size() > bestItem.bestMatch.size()) { bestItem.bestMatch = currentStr; bestItem.bestMap = iterOpt->second.vc; bestItem.remainingString = origOpt.substr(currentStr.size()); bestItem.space = iterOpt->second.space; bestItem.error = iterOpt->second.error; } } } return bestItem; }@@@ Sun Flag Mappings @@@ Simple mappings -xO1 *** /O2 !!! -xO2 *** /O2 !!! -xO3 *** /Ox !!! -xO4 *** /Ox !!! -xO5 *** /Ox !!! -xO *** /O2 !!! -O1 *** /O2 !!! -O2 *** /O2 !!! -O3 *** /Ox !!! -O4 *** /Ox !!! -O5 *** /Ox !!! -D *** /D ### -I *** /I !!! -c *** /c !!! -mt *** /MT !!! -P *** /P !!! -P *** /P !!! @@@ More involved Mappings -xspace *** /O1 !!! -386 *** /G3 !!! -486 *** /G4 !!! -cg *** see -xcg +d *** /Ob0 !!! -g *** /Zi !!! -E *** /EP !!! -g0 *** /Zi !!! -H *** /showIncludes !!! -xhelp=flags *** /? !!! -xsbfast *** /FR ### -xsb *** /FR ### -fns *** !!! -fns=yes *** !!! -fns=no *** /Op !!! -fsimple=0 *** /Op !!! -fsimple=1 *** /Op !!! -fsimple=2 *** !!! -fstore *** /Op !!! -G *** /LD !!! -o *** /Fe ### -L *** /link /LIBPATH: !!! +w *** /W4 !!! +w2 *** /Wall !!! -w *** /W1 !!! -z *** /link !!! -xwe *** /WX !!! -fast *** /Ox !!! @@@ gcc Flag Mappings @@@ Simple Mappings -Wall *** /Wall !!! -O2 *** /O2 !!! -c *** /c !!! -S *** /s !!! -O0 *** /Od !!! -O1 *** /O2 !!! -O2 *** /O2 !!! -O3 *** /Ox !!! -Os *** /O1 !!! -C *** /C !!! -P *** /P !!! -D *** /D ### -U *** /U ### -I *** /I !!! @@@ More involved Mappings -E *** /EP !!! -o *** /Fe ### --help *** /? !!! -ansi *** /Za !!! -funsigned-char *** /J !!! -pedantic *** /Za !!! -pedantic-errors *** /Za !!! -w *** /W0 !!! -ggdb *** /Zi !!! -gstabs *** /Zi !!! -gstabs+ *** /Zi !!! -gcoff *** /Zi !!! -gxcoff *** /Zi !!! -float-store *** /Op !!! -fno-default-inline *** /Ob0 !!! -fomit-frame-pointer *** /Oy !!! -fno-inline *** /Ob0 !!! -finline-functions *** /Ob2 !!! -include *** /FI !!! -nostdinc *** /X !!! -undef *** /u !!! -nodefaultlibs *** /link /NODEFAULTLIB !!! -nostdlib *** /link /NODEFAULTLIB !!! -L *** /link /LIBPATH: !!! -fpack-struct *** /Zp1 !!! -fstack-check *** /GS !!! -Wno-unknown-pragmas *** !!! -Wno-format *** !!! @@@ Fatal Errors -fvolatile *** EEE -fvolatile-global *** EEE -fvolatile-static *** EEE @@@ Warnings -Xlinker *** ^^^ -aux-info *** ^^^ -fno-asm *** ^^^ -fno-builtin *** ^^^ -fhosted *** ^^^ -ffreestanding *** ^^^ -trigraphs *** ^^^ ~~~ All Done! Nothing down here is processed. Can be used for additional comments. No mappings that I know of -a -xa -v --target-help -x -std -traditional -traditional-cpp -fcond-mismatch -fsigned-char -fwritable-strings --- sorta like /Gf -fshort-wchar -fno-access-control -fcheck-new -fconserve-space -fno-const-strings -finline-limit= -ftrapv -foptimize-sibling-calls -fkeep-inline-functions -fkeep-static-consts -fno-function-cse -fstrict-aliasing -idirafter -imacros -iprefix -iwithprefix -M -MM -MD -MMD -MF -MG -MP -MQ -MT -H -A -l -dM -dD -dN -dI -fpreprocessed -s -statuc -shared -symbolic -shared-libgcc -static-libgcc -u -I- -fshort-double -funwind-tables -fshared-data -fno-ident -pipe -pass-exit-codes#include <string> #include <iostream> #include <string.h> #include <process.h> #include "Input.h" #include "CommandLine.h" #include "ReturnItem.h" using namespace std; int main(int argc, char *argv[]) { if(argc < 2) return -1; string theOutput = "cl "; string currentArg; ReturnItem mapping; Input theInput; CommandLine theCommandLine; #ifndef CCMEMORY // if we compile to read from memory or to read from a file if(theInput.ReadInputFile("ccFile.cfg") == -1) // the file name is fixed return -1; #else theInput.CreatePairsFromCode(); #endif // here we read in the command line theCommandLine.ReadCommandLine(argc - 1, &argv); // iterate over each word in the command line while("" != (currentArg = theCommandLine.GetNextWord())) { // find the best mapping for each word mapping = theInput.BestMapping(currentArg); // create the output string if(mapping.error == FATAL) { cerr << "Error with flag " << mapping.bestMap << " -- ABORTING\n"; return -1; } if(mapping.error == WARNING) { cerr << "Warning: Flag may not be properly supported: " << mapping.bestMap << endl; } theOutput += mapping.bestMap + mapping.remainingString; if(mapping.space) theOutput += " "; } cout << theOutput << endl; // execute the generated output string. 'cl.exe' will need to be in the users path system(theOutput.c_str()); return 0; }- 人脸检测
@ - The Viola/Jones Face Detector
A seminal approach to real-time object detection Key ideas
- Integral images for fast feature evaluation
- Boosting for feature selection
- Attentional cascade for fast rejection of non-face windows
- P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features. CVPR 2001.
P. Viola and M. Jones. Robust real-time face detection. IJCV 57(2), 2004.
- Feature Computation The “Integral” image representation
- Feature Selection The AdaBoost training algorithm
Real-timeliness A cascade of classifiers
All faces share some similar properties – The eyes region is darker than the upper-cheeks. – The nose bridge region is brighter than the eyes. – That is useful domain knowledge • Need for encoding of Domain Knowledge: – Location - Size: eyes & nose bridge region – Value: darker / brighter
Integral Image Representation (check back-up slide)
Using the integral image representation we can compute the value of any rectangular sum (part of features) in constant time – For example the integral sum inside rectangle D can be computed as: ii(d) + ii(a) – ii(b) – ii(c)
Feature Computation: features must be computed as quickly as possible 2. Feature Selection: select the most discriminating features 3. Real-timeliness: must focus on potentially positive image areas (that contain faces)
- AdaBoost
- stands for “Adaptive” boost
- Constructs a “strong” classifier as a
- linear combination of weighted simple
- “weak” classifiers

parental advisory
- StackOverflow 上的一个逗逼用户==
@ this man… is … I don’t know what to say…
- utf-8 characters
@ - ☐ (hex:
☐/ dec:☐): ballot box (empty, that’s how it’s supposed to be) - ☑ (hex:
☑/ dec:☑): ballot box with check - ☒ (hex:
☒/ dec:☒): ballot box with x - ✓ (hex:
✓/ dec:✓): check mark, equivalent to✓and✓in most browsers - ✔ (hex:
✔/ dec:✔): heavy check mark - ✗ (hex:
✗/ dec:✗): ballot x - ✘ (hex:
✘/ dec:✘): heavy ballot x
居然自带颜色……难道浏览器可以对某一个特定字符设定颜色?
refs and see also
- ☐ (hex:
- Bézier Curve
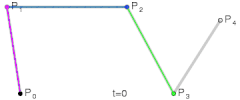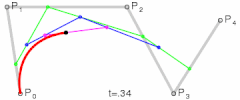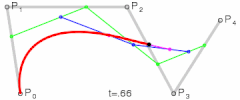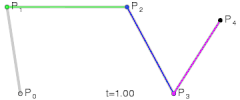
@ Try online: The Bézier Game
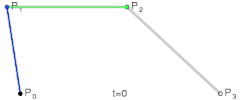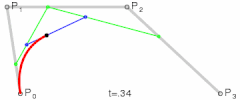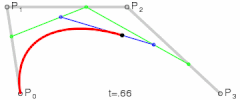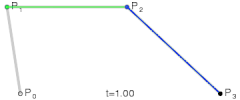
refs and see also
- 关于字体(Fonts)
@ - Computer Font
A computer font (or font) is an electronic data file containing a set of glyphs, characters, or symbols such as dingbats1. Although the term font first referred to a set of metal type sorts in one style and size, since the 1990s it is generally used to refer to a scalable set of digital shapes that may be printed at many different sizes.
There are three basic kinds of computer font file data formats:
- Bitmap fonts consist of a matrix of dots or pixels representing the image of each glyph in each face and size.
- Outline fonts (also called vector fonts) use Bézier curves, drawing instructions and mathematical formulae to describe each glyph, which make the character outlines scalable to any size.
- Stroke fonts use a series of specified lines and additional information to define the profile, or size and shape of the line in a specific face, which together describe the appearance of the glyph.
- Outline fonts
Outline fonts or vector fonts are collections of vector images, consisting of lines and curves defining the boundary of glyphs. Early vector fonts were used by vector monitors and vector plotters using their own internal fonts, usually with thin single strokes instead of thick outlined glyphs. The advent of desktop publishing brought the need for a universal standard to integrate the graphical user interface of the first Macintosh and laser printers. The term to describe the integration technology was WYSIWYG (What You See Is What You Get). The universal standard was (and still is) Adobe PostScript. Examples are PostScript Type 1 and Type 3 fonts, TrueType and OpenType.
PostScript fonts are outline font specifications developed by Adobe Systems for professional digital typesetting, which uses PostScript file format to encode font information.
- Type 1
Type 1 (also known as PostScript, PostScript Type 1, PS1, T1 or Adobe Type 1) is the font format for single-byte digital fonts for use with Adobe Type Manager software and with PostScript printers. It can support font hinting. It was originally a proprietary specification, but Adobe released the specification to third-party font manufacturers provided that all Type 1 fonts adhere to it.
Type 1 fonts are natively supported in Mac OS X, and in Windows XP and later via the GDI API. (They are not supported in the Windows GDI+, WPF or DirectWrite APIs.)
Type 2, 3, 4, 5, 9, 10, 11, 14, 32, 42
TrueType is an outline font standard developed by Apple and Microsoft in the late 1980s as a competitor to Adobe’s Type 1 fonts used in PostScript. It has become the most common format for fonts on both the Mac OS and Microsoft Windows operating systems.
The primary strength of TrueType was originally that it offered font developers a high degree of control over precisely how their fonts are displayed, right down to particular pixels, at various font sizes. With widely varying rendering technologies in use today, pixel-level control is no longer certain in a TrueType font.
OpenType is a format for scalable computer fonts. It was built on its predecessor TrueType, retaining TrueType’s basic structure and adding many intricate(复杂的) data structures for prescribing typographic behavior. OpenType is a registered trademark of Microsoft Corporation.
refs and see also
设置 Git 的 Upstream@# 看看当前的 upstream $ git remote -v origin git@github.com:district10/blog.git (fetch) origin git@github.com:district10/blog.git (push) # 添加一个 $ git remote add coding https://git.coding.net/dvorak4tzx/blog.git # 看看是否加入成功 $ git remote -v coding https://git.coding.net/dvorak4tzx/blog.git (fetch) coding https://git.coding.net/dvorak4tzx/blog.git (push) origin git@github.com:district10/blog.git (fetch) origin git@github.com:district10/blog.git (push) # 把代码传上去 $ git push coding master # 重命名一个 upstream git remote rename coding backup # 换个 url $ git remote set-url backup git@github.com:USERNAME/OTHERREPOSITORY.git # 删除 upstream $ git remote rm backup # 补充点备忘(`user.name` 和 `user.email` 就不说了) $ git config --global core.editor vim $ git remote add origin url.git $ git push origin masterrefs and see also
- QQ 表情
@ 不算好看。但也凑合。
01 02 03 04 05 06 07 08 09 10 A 









B 









C 









D 









E 









F 









G 









H 









I 









J 









K 









L 









M 









N 





- replay a vim macro until end of buffer - Stack Overflow
@ Vim Macro
就跟其它所有编辑器一样,宏很好用。
但我不知道在 Vim 里怎么 apply 一个 macro 到文件末尾(在 Notepad++ 里很容易)。
查到的是:
VG:normal @x或者:%normal @x,总之就是在一定范围内,用:normal @x。- NetBIOS Names
@ 我不知道我看这个干嘛……
Character ASCII Code Hex Code A EB 45 42 B EC 45 43 C ED 45 44 D EE 45 45 E EF 45 46 F EG 45 47 G EH 45 48 … … … NOTE: The above mapping list can be useful while reading network traces because information is sent on the wire in the above encoded format.
(世上还有这么神奇的表示法。)
refs and see also
- HTML Entity
@ 在 Learning HTML 里有部分笔记。但感觉不够,有时候我都开始用 LaTeX 来标记,但那也太蠢了……
℃,℉,★,☆,☺,☻,☼
- "
" - &
& -
- ¥
¥ - ¦
¦broken vertical bar - §
§ - «
«left double angle quotes - »
» - °
° - ±
±plus minus - µ
µ - ¶
¶ - ¿
¿ - ¼
¼ - ½
½ - ¾
¾ - ×
× - ÷
÷ - æ
ælatin small letter ae - •
•bullet - …
…horizontal ellipsis - ′
′ - ″
″ - ⁄
⁄fraction slash - ←
← - →
→ - ↑
↑ - ↓
↓ - ↔
↔ - ⇐
⇐ - ⇒
⇒ - ⇑
♥ - ⇓
⇓ - ⇔
⇔ - ↵
↵downwards arrow wiht corner leftwards (carriage return) - ¬
¬ - ∀
∀ - ∃
∃ - ∂
∂ - ∇
∇['næblə], 劈形算符;微分算符 - ∈
∈ - ∉
∉ - ∋
∋ - ∏
∏ - ∑
∑ - −
− - ∗
∗asterisk - √
√square root - ∝
∝ - ∞
∞ - ∠
∠ - ∧
∧ - ∨
∨ - ∩
∩ - ∪
∪ - ∫
∫integral - ∴
∴therefore - ≅
≅approximately equal to - ≈
≈almost equal to - ≠
≠ - ≡
≡ - <
< - >
> - ≤
≤ - ≥
≥ - ⊂
⊂subset - ⊃
⊃superset - ⊆
⊆ - ⊇
⊇ - ⊄
⊄ - ⊕
⊕circled plus - ⊗
⊗circled times - ⊥
⊥up tack - ⋅
⋅ - ⌈
⌈ - ⌉
⌉ - ⌊
⌊ - ⌋
⌋ - ⟨
⟨ - ⟩
⟩ - ◊
◊lozenge,['lɑzɪndʒ], 菱形 - ♥
♥

WWII “ruptured duck” Honorable Discharge Emblem lozenge
refs and see also
- "
Assignment Expression@An assignment expression has the value of the left operand after the assignment.
出自 C99 standard, section 6.5.16
- 有赋值表达式的情况下
if result=func1(...): print func2(result)- 无赋值表达式的情况下
result=func1(...) if result: print func2(result)
然后你就知道什么叫赋值表达式了。
- Python:
import this=> The Zen of Python, by Tim Peters Beautiful is better than ugly. **Explicit is better than implicit.** Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than right now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
refs and see also
- Citation signal - Wikipedia, the free encyclopedia
@ A Legal citation signal or introductory signal is a set of brief abbreviated phrases or words used to clarify the authority or significance of a legal citation as it relates to a proposition.
- Signal Details
Signals that indicate support
- no signal(直接在后面把引用列出来)
- e.g., “exempli gratia”(比如说) > The placebo effect is well established. See, e.g., Anne Harrington, The Placebo Effect: An Interdisciplinary Exploration (1999).
- Accord(还有,也)
- “I have just cited something that supports my proposition, and now here’s another thing that supports it too.”
- See(这个很直接,不解释了)
- See also
- Cf., compare(就像是说:“他们也是类似的观点”)
The Massachusetts Court of Appeals did not reach that question and we decline to address it in the first instance. Cf. Coy v. Iowa, 487 U.S. 1012, 1021-1022, 108 S.Ct. 2798, 101 L.Ed.2d 857 (1988).
- Signals that indicate background material
- See generally
- Signals that indicate contradiction
- Contra
- But see
- But cf.
- Signals that indicate a useful comparison
- Compare _____ with _______
- Using signals as verbs(这是在 footnote 里常用的)
See Christina L. Anderson, Comment, Double Jeopardy: The Modern Dilemma for Juvenile Justice, 152 U. Pa. L. Rev. 1181, 1204-07 (2004) (discussing four main types of restorative justice programs).
- “Cf.” becomes “compare” and “e.g.” becomes “for example” when these signals are used as verbs.
- Signal formatting(TODO)
Read more | 下面是关于 citation 和英文写作比较著名的几本书
- Signal Details
- 裘宗燕主页 :: Main Page of Qiu Zongyan
@ 从 C Traps and Pitfalls 看到这里。这老师很著名。
里面有一些课程:
- 2015 年春季课程:计算概论(基于 Python 的课程)
- 2014 年秋季课程:数据结构(基于 Python 的课程)
- 2014 年春季课程:计算概论(基于 Python 的课程)
- 2014 年春季课程:程序设计技术与方法(面向数学学院和信息学院三年级本科生)采用 MIT 的著名教科书 Structure and Interpretation of Computer Programs。
- 2012 年秋季课程:程序设计技术与方法
- 2012 年春季课程:程序设计语言原理(研究生课程)
- 2011 年秋季课程:程序设计技术与方法
- 2010 年秋季课程:程序设计技术与方法
- 2010 年秋季课程:算法与数据结构 — 基于 Maple 的课程
- 2010 年春季课程:形式化方法 — 基于 B 方法的软件开发(研究生课)
- 2010 年春季课程:低年级讨论班(软件)
- 2009 年秋季课程:程序设计技术与方法
- Requirements for Chinese Text Layout 中文排版需求
@ -
句號
U+3002IDEOGRAPHIC FULL STOP[。]、逗號U+FF0CFULLWIDTH COMMA[,]以及頓號U+3001IDEOGRAPHIC COMMA[、]。句號表示語句結束、逗點表示語氣停頓、頓號使用於並列連用、表示次序的字詞之間。許多理工書籍、科技文獻、西文教科书语法书籍等內含大量西文詞句,並採用橫排,為求標點符號體例一致,也有採用
U+FF0EFULLWIDTH FULL STOP[.]為句號、採U+002CCOMMA[,]或U+FF0CFULLWIDTH COMMA[,]為逗號與頓號的案例。2橫排時,西文使用比例字體;阿拉伯數字則常用比例字體或等寬字體。原則上,漢字與西文字母、數字間使用四分之一個漢字寬的字距或空白。但西文出現在行頭或行尾時,則毋須加入空白。(最好中英文就之间加个空格,see [中文排版指北])或可使用西文詞間空格(U+0020 SPACE [ ],其寬度隨不同字體有所變化)。
- Caliphate - Wikipedia, the free encyclopedia
@ 哈里发,
key-lif, kal-if“Je suis Charlie” (French pronunciation:
[ʒə sɥi ʃaʁli], French for “I am Charlie”) is a slogan and a logo created by French art director Joachim Roncin and adopted by supporters of freedom of speech and freedom of the press after the 7 January 2015 massacre in which twelve people were killed at the offices of the French satirical weekly newspaper Charlie Hebdo.
The front cover of edition of 14 January 2015, with a cartoon in the same style as 3 November 2011 cover, uses the phrase “Je suis Charlie”
French terror attacks: Victim obituaries3
Twelve people died when a bloody attack was launched on the office of France’s satirical magazine Charlie Hebdo. The following day a policewoman was murdered by Amedy Coulibaly, who held up a Jewish supermarket the next day, killing four people. Here are brief profiles of all 17 victims.

19 Sep 2012 issue: An Orthodox Jew pushes an old Muslim in a wheelchair, both shouting “You mustn’t make fun!”
死的很多 cartoonist 和 editor,以及一两个 economist,
警察里有 Ahmed Merabet,是个 muslim,“He was a Muslim - a fact picked up by bloggers seeking to defend the community against”terrorist" slurs."
Witnesses have been describing the dramatic events in France, where two sieges came to a violent end.
Hostage’s mother:
“My daughter, she’s in the supermarket. She’s with her Jewish boyfriend. They went shopping. he called me 10 minutes ago. She said mum - there’s dead people.”
Golda, shopper
“There is a big Jewish community in the area - this area is actually in the middle of three Jewish communities.”Do I feel threatened? Yes. For the Jewish community, once again we are being attacked."

Video footage showed two gunmen firing assault weapons at police in the street outside the office

France has been left reeling from the brutal attack
- ‘Rivers of blood’
One witness told AFP the attack was reminiscent of a scene from a movie: “I saw them leaving and shooting. They were wearing masks. These guys were serious…. At first I thought it was special forces chasing drug traffickers or something.”

Vigil(
戒严祈福) held in Sète, France
Police officers stand guard outside a flat in Reims as investigators search inside.

Rallies condemning the attack are taking place across the world, including this one in Quebec, Canada.

Cartoon by Alex Green

Barbaric

Victims lay on the pavement in a Paris restaurant Nov. 13, 2015.
法国人唱着国歌撤离球场。
Ernest Hemingway (For Whom the Bell Tolls):
不要问丧钟为谁鸣,丧钟为你而鸣。
refs and see also
- French terror attacks: Victim obituaries - BBC News
- France sieges end: Witness accounts - BBC News
- As it happened: Charlie Hebdo attack - BBC News
- Charlie Hebdo: Gun attack on French magazine kills 12 - BBC News
- Paris attacks: Suspects’ profiles - BBC News
- Paris attacks: Dozens killed in series of terror attacks across French capital - CBS News
- Je suis Charlie - Wikipedia, the free encyclopedia
- 我的 Markded 模板
@ - http://whudoc.qiniudn.com/2016/v/0.2/marked.html
<!doctype html> <html> <head> <meta charset="utf-8"/> <title>Marked in the browser</title> </head> <body> <div class="tzxMarked">**nice**</div> <div class="tzxMarked"> # good **bad** ## nice ## terrible > quoted </div> <script src="http://tangzx.qiniudn.com/marked.js"></script> <script> tzxMarkeds = document.getElementsByClassName('tzxMarked'); for ( var i = 0; i < tzxMarkeds.length; ++i ) { m = tzxMarkeds[i]; ms = m.textContent; console.log( ms ); m.innerHTML = marked( ms ); } </script> </body> </html>
- 我的 Strapdown 模板
@ - http://whudoc.qiniudn.com/2016/v/0.2/united.html
<!DOCTYPE html> <html> <title>Hello Strapdown</title> <xmp theme="united" style="display:none;"> # Markdown text goes in here theme: united ## Chapter 1 chapter one! **bold** and *slanted*. - foo - bar 1. one 2. two `bash -e "echo hello"` ## Chapter 2 <http://tangzx.qiniudn.com/>  </xmp> <script src="http://whudoc.qiniudn.com/2016/v/0.2/strapdown.js"></script> </html>
更多例子见:http://whudoc.qiniudn.com/2016/v/0.2/index.html
refs and see also
- Ballot Box
@ - Unicode Block (Miscellaneous Symbols)
U+2600~U+26FF, #characters = 256- BALLOT BOX WITH CHECK
- ☑
☑ - BALLOT BOX
- ☐
☐
ballot 英
['bælət]美['bælət]n. 投票;投票用纸;投票总数 vi. 投票;抽签决定refs and see also
Facility location problem - Wikipedia, the free encyclopedia
Core fonts for the Web - Wikipedia, the free encyclopedia
dwtkns/gdal-cheat-sheet: Cheat sheet for GDAL/OGR command-line tools
pandoc-templates/default.html at master · kjhealy/pandoc-templates
- Extension to pandoc’s markdown similar to Gitbook, using a “Web template system” · Issue #2676 · jgm/pandoc
@ jgm 大神说这个文件替换自己处理就好,加到 pandoc 里的话需要处理太多麻烦事。
- Google Earth
@ Viewing Your Model in Google Earth | SketchUp Knowledge Base
Viewing Your Model in Google Earth | SketchUp Knowledge Base
Intro to Importing Data into Google Earth
Downloading, Installing, and Authorizing SketchUp 2016 | SketchUp Knowledge Base
Blender to Google Earth Workshop
OpenSceneGraph Max Exporter download | SourceForge.net
Spatial References — osgEarth 2.4 documentation
Terrain Tools & Software - Commercial
- Free OpenSceneGraph Binary Downloads | AlphaPixel
@ osg binary.
How to remove, copy or rename a file with Perl
How do I get the full path to a Perl script that is executing? - Stack Overflow
css - @Media min-width & max-width - Stack Overflow
miloyip/itoa-benchmark: C++ integer-to-string conversion benchmark
- JoakimSoderberg/catcierge: Image recognition (to keep cat prey out) and RFID chip reader system for automated DIY cat door.
@ 完整的展示了 travis 之类的使用,多平台的编译、测试,等等。
- git - Download a single folder or directory from a GitHub repo - Stack Overflow
@ This is a pretty old question, but I figured this out today and I thought I’d leave this here for anyone else who has the same problem.
As all the previous answers have already noted, you are not allowed to download a single folder using Git. However, you ARE allowed to do this with subversion. This won’t work on a regular git repo obviously, but if you’re using GitHub you can actually check out using svn.
For example:
svn checkout https://github.com/foobar/Test/trunk/footrunk corresponds to master branch. You can use svn ls to see available tags and branches before downloading if you wish. If you want a folder in a branch other than master then replace trunk with branches/branchname.
As of this writing, you can find the subversion URL for any repo on GitHub by clicking on “Subversion” at the bottom of the right sidebar. See GitHub’s post on subversion partial checkouts for more info.
Preface | Data Structure and Algorithm notes
- 500 Lines or Less
@ - Coding 演示平台
@ 从某种程度上说,coding.net 比 github.com 厚道得多。
我收回上面那句话。
- Jekyll 迁移到 Hexo 建立个人博客 | Lippi- 浮生志
@ 个人博客以前由 jekyll 搭建,主要问题是目录、Rss、sitemap 无法自动生成,根据 DRY 的原则在网上找了下答案,最终发现了用 Hexo 来搭建博客的方法,配置完之后一劳永逸,目录、Rss 和 sitemap 都是自动生成,解决了我之前的困惑。
TODO: 去看它的 rss 怎么生成的。
IntroPy - Woodpecker Wiki for CPUG
top10-Py-idioms-wish-learned-earlier | #是也乎# | ZoomQuiet.io
Cpp-Primer/ch01 at master · Mooophy/Cpp-Primer
CppCoreGuidelines/CppCoreGuidelines.md at master · isocpp/CppCoreGuidelines
Crosswalk - build world class hybrid apps
AGWA/git-crypt: Transparent file encryption in git
glsltuto/shaders at master · ssloy/glsltuto
FlatBuffers: Using the schema compiler
dvidelabs/flatcc: FlatBuffers Compiler and Library in C for C
ocornut/imgui: Bloat-free Immediate Mode Graphical User interface for C++ with minimal dependencies
- zealdocs/zeal: Offline documentation browser inspired by Dash
@ Document tool: dash, zeal
SICP终于看完了,有一些经验想分享出来 - 学习资料 - CoCode
- c++ - Linking different libraries for Debug and Release builds in Cmake on windows? - Stack Overflow
@ You should not test
CMAKE_BUILD_TYPEin the CMake file, it is ignored by multi configuration generators (like VS). If you run cmake withCMAKE_BUILD_TYPE=Debugbut Release in VS the code inif(CMAKE_BUILD_TYPE MATCHES Release)is simply ineffective.
OSG+VS2010+win7 环境搭建 - 缑城浪子 - 博客园
ClangFormat — Clang 3.9 documentation
Chiel92/vim-autoformat: Provide easy code formatting in Vim by integrating existing code formatters.
jquery - Auto-size dynamic text to fill fixed size container - Stack Overflow
Reference Counted Objects in OSG and Producer
- qt+osg+vs2008中(msvcr90.dll) 处最可能的异常: 0xC0000005的问题解决 - xhcumt的专栏 - 博客频道 - CSDN.NET
@ 同样在官方论坛上找到答案:是Project属性配置引起的,
Project Properties->Configuration Properties->C/C++->Code Generation->Runtime Library,- 把
Multi-threaded Debug DLL (/MDd)改为Multi-threaded DLL (/MD), 而/MDd是 Debug 的默认选项. 不过文中提到的有关”_DEBUG”改为”NDEBUG”倒不必.
File and Disk Utilities: Sysinternals Center
Windows Sysinternals: Documentation, downloads and additional resources
Learn how to use Microsoft Windows 7 | Easier faster computing
- How to Copy and Paste in the Windows Command Prompt | Gizmo’s Freeware
@ - CMD, click the icon, in config, turn on quick edit mode.
- CMD, Alt-Space, E(dit), P(aste)
A few links for peoples frequently using the command prompt or a shell:
- ConEmu http://code.google.com/p/conemu-maximus5/ 推荐
A console emulator with tabs, it works fine with everything listed below. (It allows line/block selection for copying.)
- CygWin http://cygwin.com/
This is a HUGE collection of gnu/linux tools for windows, from bash to zsh, perl, gcc, mc… If you’re a linux guy, you’ll feel at home with this.
- TCC/LE http://jpsoft.com/
It’s 4DOS, an enhanced cmd.exe, a must have. (Like NDOS)
- FAR Manager http://farmanager.com/
Norton commander clone.
- SysInternals Suite http://sysinternals.com/
Various command-line and gui tools: process, junctions, etc.
- NirCMD http://www.nirsoft.net/utils/nircmd.html
Small utility that allows you to do some useful windows tasks.
- CLink https://code.google.com/p/clink/
Better completion for cmd.exe
I hope someone might find this helpful.
- moment/momentjs.com: The website for momentjs
@ 效果很好。
refs and see also
- vim - How do I open the directory of the current open file? - Super User
@ :Sex .This is good but the command is so hard to remember.
其实用
:E就可以啊……refs and see also
Things I Wish I Learned In Engineering School
- 【新智元—世纪对决】AlphaGo 惊天逆转李世石 ,关键棋局解析
@ Go (traditional Chinese: 圍棋; simplified Chinese: 围棋; pinyin: About this sound wéiqí; Japanese: 囲碁; rōmaji: igo; literally: “encircling game”) is an abstract board game for two players, in which the aim is to surround more territory than the opponent.
The game originated in ancient China more than 2,500 years ago, and is one of the oldest board games played today. It was considered one of the four essential arts of a cultured Chinese scholar in antiquity. The earliest written reference to the game is generally recognized as the historical annal Zuo Zhuan.
There is much strategy involved in the game, and the number of possible games is vast (10761 compared, for example, to the estimated 10120 possible in chess), displaying its complexity despite relatively simple rules.
refs and see also
javascript - Copy to clipboard without Flash - Stack Overflow
- 日常生活中有哪些十分钟就能学会但是终生受用的技能? - 知乎
@ refs and see also
- 你最推荐的 Chrome 扩展有哪些? - 知乎
- Unix 传奇 (上篇) | 酷 壳 - CoolShell.cn
- Unix 传奇 (下篇) | 酷 壳 - CoolShell.cn
- 黑客的价值观 | 酷 壳 - CoolShell.cn
- 计算机编程简史图 | 酷 壳 - CoolShell.cn
- 李开复每天早上 4 点就起床,是怎么办到的?开复老师如何能很好地安排好自己的时间? - 知乎
- 财经郎眼 20140603 喜忧参半的 4G 时代 - 视频在线观看 - 财经郎眼 - 财经 - 爱奇艺
- 聊聊我在 Google 无人车研究组的那些事 | 36 氪
- 如何应对一群 13 - 18 岁的街头小混混的挑衅? - 知乎
- 讲一讲汉尼拔·莱克特博士。 (汉尼拔 影评)
- Why Is Rho Used for Density? | eHow
- 求知成瘾,却无作品 | 简书
- 如何成功地早起 | 简书
- 三分钟学会希腊语 | 简书
- 哥们儿,你的所有病都是一种病 | 简书
- 嘿,那个上了三天班就辞职的年轻人,我想和你谈谈! | 简书
- 万苦皆因怂 | 简书
- 如何坚持每天写一千字 | 简书
- 你以为你在合群,其实你只在浪费青春 | 简书
- Javascript 的前后端统一是个“笑话”吗? | 简书
- 在你被人认识之前 | 简书
- 别把你最好的东西给我 | 简书
- 诚信逆向淘汰的社会 | 简书
- 一份关于如何改变人生的指南 | 简书
- 记一次嫖娼 | 简书
- 那些年,坐我们前排的土豪和学霸 | 简书
- 从那道并不变态的家庭作业说起,兼答邓飞 | 简书
- 欲望少女养成记 | 简书
- 你不是书读得少,你是经典读得少 | 简书
- 你会因文字而爱上一个人吗 | 简书
- 不着调的海小姐 | 简书
- 两条写作建议 | 简书
- 别跟这个世界讲道理 | 简书
- 中国式道德审判 | 简书
- 信息时代如何使用你的大脑? | 简书
- 安静的力量 | 简书
- 那些年,我麻烦过的人 | 简书
- 一个人看电影 | 简书
- 如果让我再读一次本科 | 简书
- “文艺青年”与“装逼犯” | 简书
- 为什么我们无法深入交谈 | 简书
- 我的儿子不可能平庸 - 简书
- Help:Displaying a formula - Wikipedia, the free encyclopedia
@ refs and see also
- List of mathematical symbols - Wikipedia, the free encyclopedia
- Mathematical operators and symbols in Unicode - Wikipedia, the free encyclopedia
- Help:Displaying a formula - Wikipedia, the free encyclopedia
- Full stop - Wikipedia, the free encyclopedia
- Quotation Marks: Where Do the Periods and Commas Go–And Why?
- Quotation mark - Wikipedia, the free encyclopedia
- Sentence spacing - Wikipedia, the free encyclopedia
- Decimal mark - Wikipedia, the free encyclopedia
- Ampersand - Wikipedia, the free encyclopedia
- Appropriate use of the ampersand | Typophile
- International System of Units - Wikipedia, the free encyclopedia
- Citation | Wikipedia
- Citation Standards | Citation Working Group
- CSL - Citation Style Language
- CSL - Styles | GitHub
- Pandoc Package - CiteProc
- DARPA 开始研发新一代的垂直起降飞机
@ 天网的背景音乐……
Dwarf Fortress - Wikipedia, the free encyclopedia
Roguelike - Wikipedia, the free encyclopedia
- Metal Slug - Wikipedia, the free encyclopedia
@ 
Super Vehicle-001: Metal Slug (メタルスラッグ Metaru Suraggu), more commonly known as simply Metal Slug, is a run and gun video game developed and originally released by Nazca Corporation and later published by SNK. It was originally released in 1996 for the Neo Geo MVS arcade platform. The game is widely known for its sense of humor, fluid hand-drawn animation, and fast paced two-player action. It is the first title in the Metal Slug series. It has been ported to the Neo Geo AES, Neo Geo CD, Sega Saturn, PlayStation, Virtual Console, PlayStation Network, iOS, Android and Neo Geo X, and to the Wii, PlayStation Portable and PlayStation 2 (as part of the Metal Slug Anthology).
Action game - Wikipedia, the free encyclopedia
alt.org - Public NetHack Server
- twitter/typeahead.js: typeahead.js is a fast and fully-featured autocomplete library
@ TODO: 替换掉 autocomplete
崔添翼 § 翼若垂天之云 › 谁能看出这是个文科生?——关于matrix67
把梦想“码”进现实 ——访计算机学院2013届校友崔添翼-学院动态-浙江大学计算机科学与技术学院中文站
Qt 学习之路 2 | DevBean’s World - Part 2
解读 Rob Pike 编写的正则表达式程序 - 开源中国社区
你所读的计算机科学方向,有哪些不错的讲义(Notes)? - 书籍推荐 - 知乎
CSCI-UA.0202: Operating Systems (Undergrad)
java - Why is processing a sorted array faster than an unsorted array? - Stack Overflow
- shell - How to run a series of vim commands from command prompt - Stack Overflow
@ for %a in (A,B,C,D) do vim -c ":g/^\s*$/d" -c "<another command>" %a.txt:help bufdo- Vim Regular Expressions 101
@ \h, head of word character (a,b,c...z,A,B,C...Z and _) \H, non-head of word character \s, whitespace, \S, non-whitespace \d, digit \D, non-digit \x, hex digit \X, non-hex digit \o, octal digit \O, non-octal digit \<, word boundary \>, word boundary \p, printable character \P, like \p, but excluding digits \w, word character \W, non-word character \a, alphabetic character \A, non-alphabetic character \l, lowercase character \L, non-lowercase character \u, uppercase character \U, non-uppercase character *, \+, \=, matches 0 or 1 more of the preceding characters... \{n,m}, \{n}, \{,m}, \{n,} \{-}, nongreedy, ".\{-}" will match the first quoted text: \{-}, matches 0 or more of the preceding atom, as few as possible \{-n,m}, matches 1 or more of the preceding characters... \{-n,}, matches at lease or more of the preceding characters... \{-,m}, matches 1 or more of the preceding characters... :s:.\{-}:_:g n and m are decimal numbers between _n_ _a_n_d_ _m_ _a_r_e_ _d_e_c_i_m_a_l_ _n_u_m_b_e_r_s_ _b_e_t_w_e_e_n_TODO
- 4.4 Character ranges
- 4.5 Grouping and Backreferences
- 4.6 Alternations
Search patterns - Vim Tips Wiki - Wikia
Org Mode - Organize Your Life In Plain Text!
Lessons on development of 64-bit C/C++ applications
深入理解学习Git工作流(git-workflow-tutorial) - SegmentFault
www.computervisionblog.com/2015/06/deep-down-rabbit-hole-cvpr-2015-and.html
18-645: How to Write Fast Code
- ASCIIFlow Infinity
@ 我把 AsciiFlow 挪过来了,可以在
使用。或者下载离线 http://whudoc.qiniudn.com/asciiflow.7z
TODO: 给它加一套键盘快捷键。
- 比尔华纳博士《我们因何而恐惧: 一个一千四百年的秘密》-纪录片视频-爱奇艺
@ 说 islam,如此地政治不正确哈哈哈。
其实历史永远是血腥的。
- Digital rights management - Wikipedia, the free encyclopedia
@ Digital rights management (DRM) schemes are various access control technologies that are used to restrict usage of proprietary hardware and copyrighted works. DRM technologies try to control the use, modification, and distribution of copyrighted works (such as software and multimedia content), as well as systems within devices that enforce these policies.
Search patterns - Vim Tips Wiki - Wikia
- git status - list last modified date - Stack Overflow
@ git status -s | \ while read mode file; do \ echo $mode $(date --reference=$file +"%Y-%m-%d %H:%M:%S") $file; \ done